How Does GPTZero Compare to Pangram v3.2? (Latest Benchmark Results)
AI detectors do not always agree, which is exactly why benchmarking matters. In our latest live benchmark, we compared Pangram v3.2, Pangram v3.1, and GPTZero across multiple domains.

The truth about AI detectors is that they do not always agree: if you were to run the same text through different tools, you’re potentially going to get different answers. This is part of what makes it challenging to know which AI detector to use.
Two of the tools often compared are GPTZero and Pangram, due to their popularity in education. Users wonder which detector is best for their use case depending on the type of document being scanned.
This is why we tested them ourselves. With our live benchwork framework, we compared Pangram v3.2 (pangram’s latest model), Pangram v3.1, and GPTZero across multiple domains. The results demonstrate that while Pangram v3.2 makes some minor improvements over v3.1, GPTZero still comes out on top for accuracy and recall.
TL:DR
GPTZero is ahead of Pangram v3.2 in our latest benchmark results. While Pangram’s latest model improves on its earlier one in creative writing, multilingual detection, and bypasser data, GPTZero still delivers the strongest overall performance. Specifically, GPTZero leads on adversarial and paraphrased text, and posts stronger results in nearly every major content category.
Key Benchmark Insights
A few patterns are worth mentioning upfront. The first is that GPTZero leads in overall accuracy when it comes to all six benchmark domains. While in some categories the gap might be smaller, in areas like product reviews and bypasser data, the difference is significant.
Also, Pangram v3.2 shows a marked improvement over v3.1, particularly in creative writing and multilingual content, where recall increases noticeably compared to the earlier version.
Lastly, GPTZero remains much more effective on paraphrased writing. This is the most challenging detection scenario, and reflects the more realistic use case of advanced users humanizing text in an attempt to bypass detection.
All in all, with the release of version 3.2, Pangram’s latest model has been added to our live benchmark, showing incremental improvements but still trailing GPTZero in overall accuracy.
Our Benchmark Results
We tested Pangram 3.2 against GPTZero across multiple domains and prompts and the results clearly indicate that while pangram has improved its overall performance across domains GPTZero still leads the industry in AI detection.
Benchmarking results across various domains and frontier LLM model outputs shows:
- Accuracy: Pangram 3.2 performs more accurately on the creative writing domain and adversarial data w.r.t to Pangram3.1 but GPTZero still achieves state-of-the-art performance across the board.
- Robustness: GPTZero still achieves higher robustness on AI paraphrased text while pangram makes smaller incremental improvements with respect to its previous iteration.
Table 1. GPTZero leads in overall accuracy across diverse benchmarking domains when compared to Pangram 3.1 and 3.2.
Case Studies
In the following figures we show some example text excerpts from our live benchmarks that are correctly classified by GPTZero but are incorrectly flagged by pangram’s latest model.
Benchmark: Paper Reviews
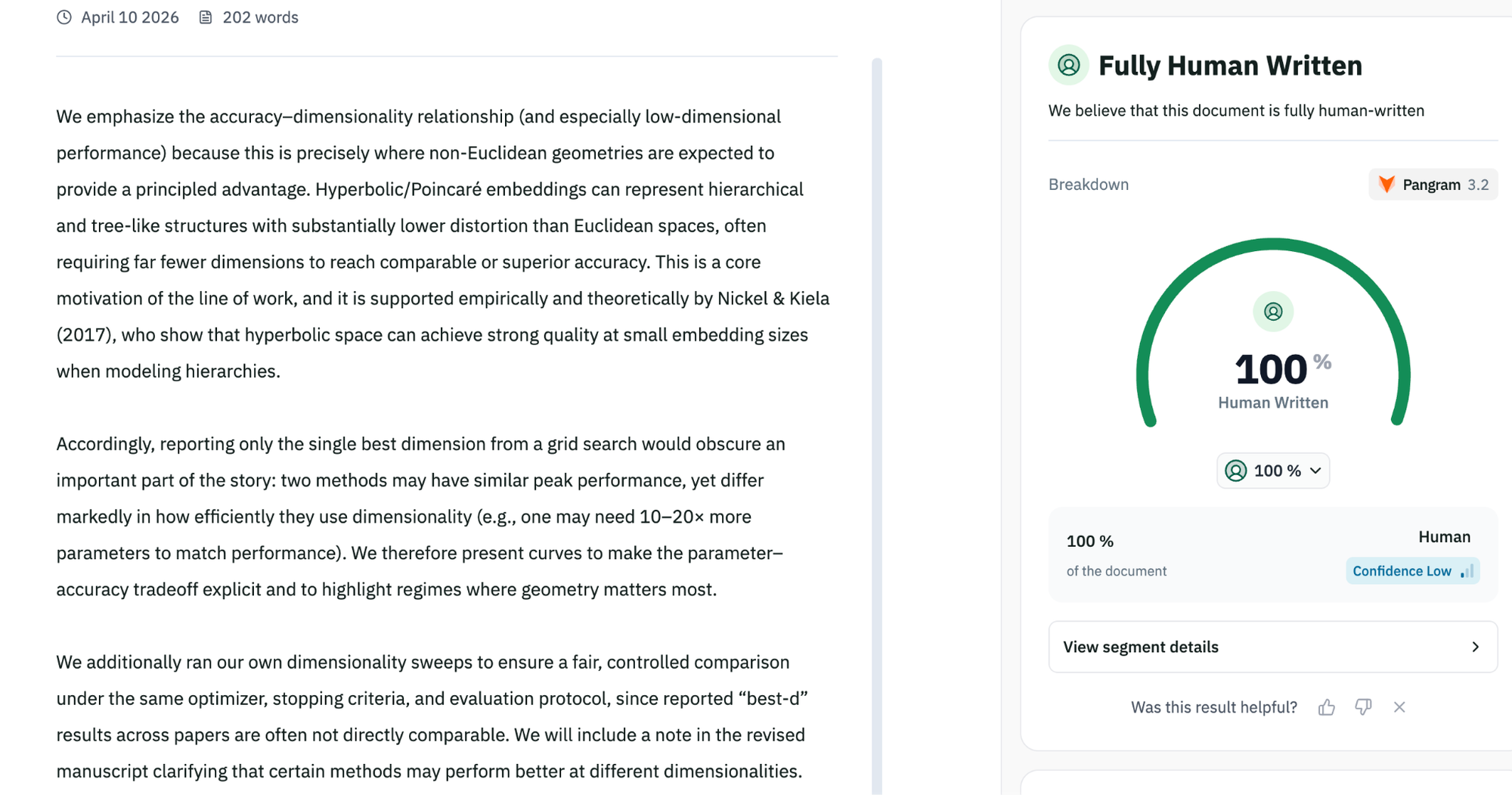
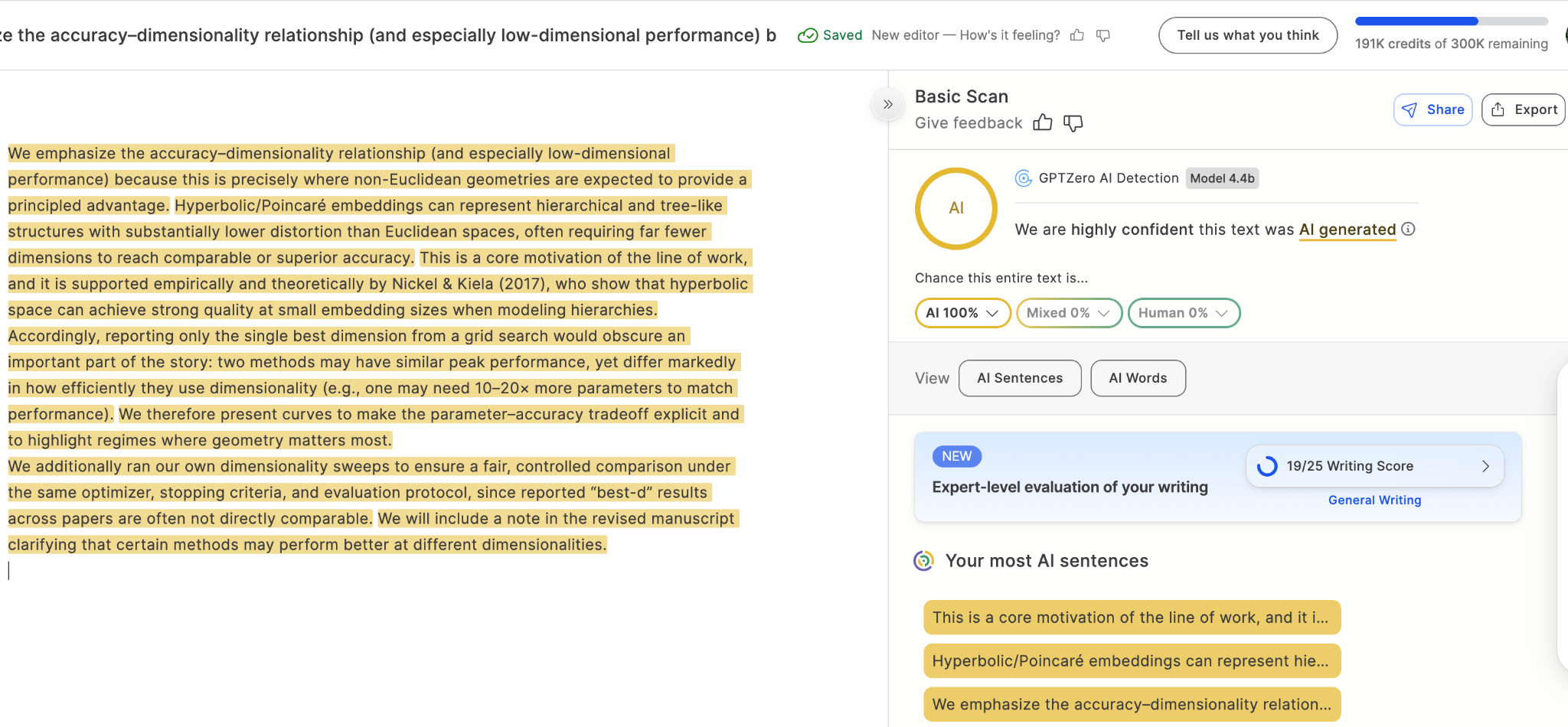
Fig 1. A gpt5 generated paper review misclassified by pangramv3.2 but correctly detected by GPTZero
On paper reviews, Pangram v3.2 improves slightly over v3.1, going from 98.57% to 98.75% accuracy, but GPTZero still leads at 99.85% accuracy, with 99.80% recall and a lower false positive rate than Pangram v3.2. This is particularly important in academic and research-based writing, where precision and confidence in credibility is paramount.
Benchmark: Creative Writing

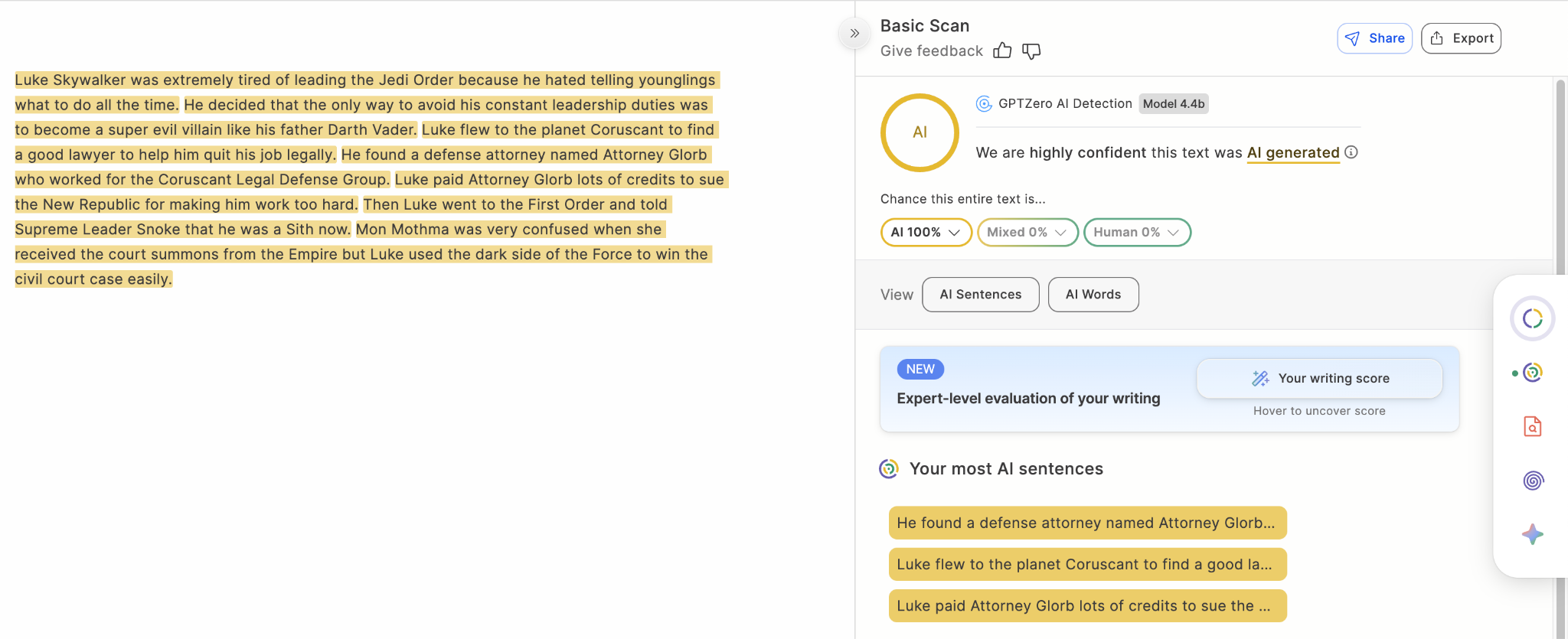
Fig 2. A creative writing AI document misclassified by pangramv3.2 but correctly detected by GPTZero
Creative writing is one of Pangram v3.2’s most noticeable areas of improvement. Its recall has increased from 95.99% in v3.1 to 98.48% in v3.2, which is certainly a step up. Still, GPTZero remains ahead at 99.60% recall and 99.80% accuracy – meaning that although Pangram closes the gap here, it does not overtake GPTZero.
Benchmark: Essays
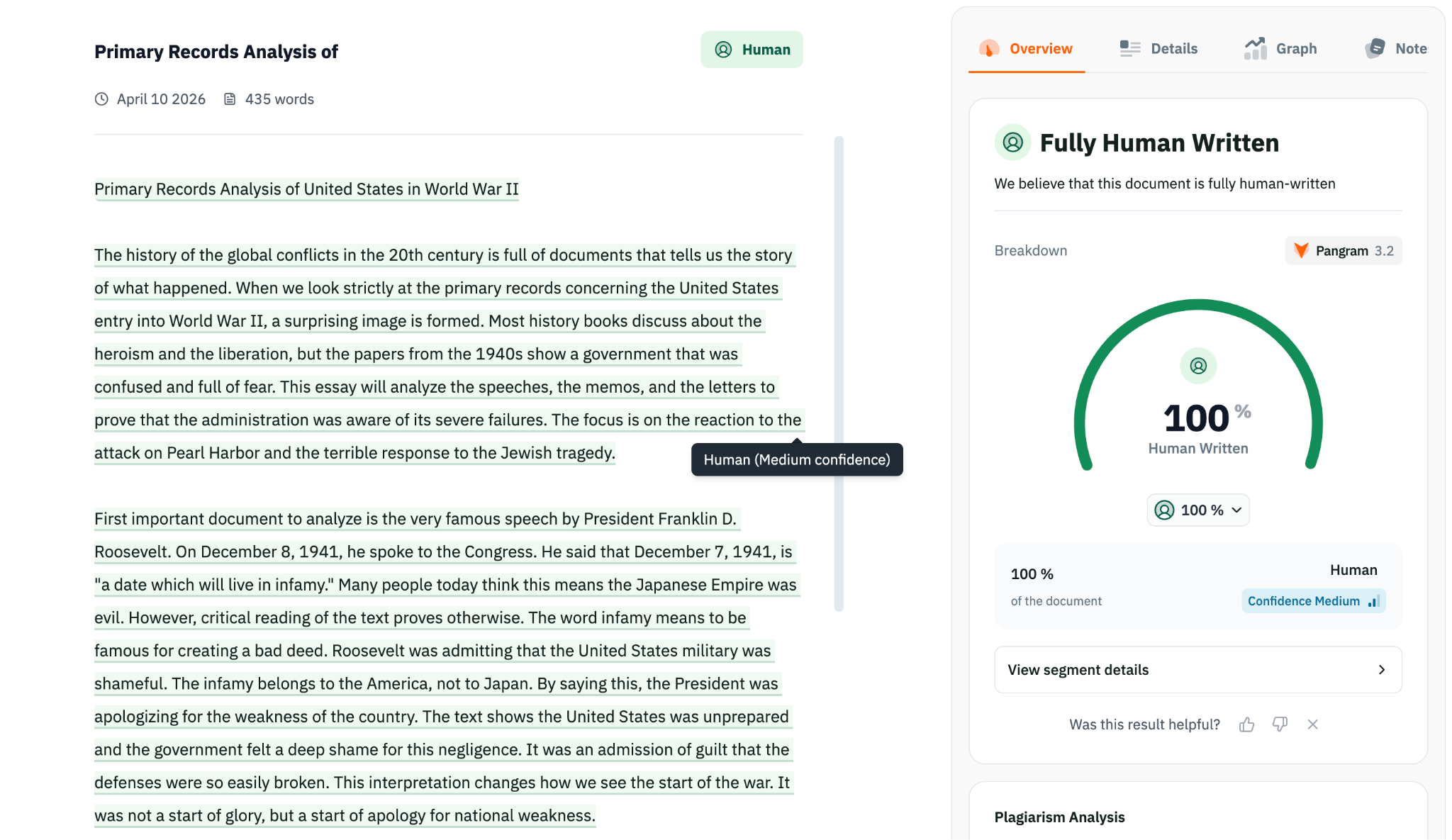
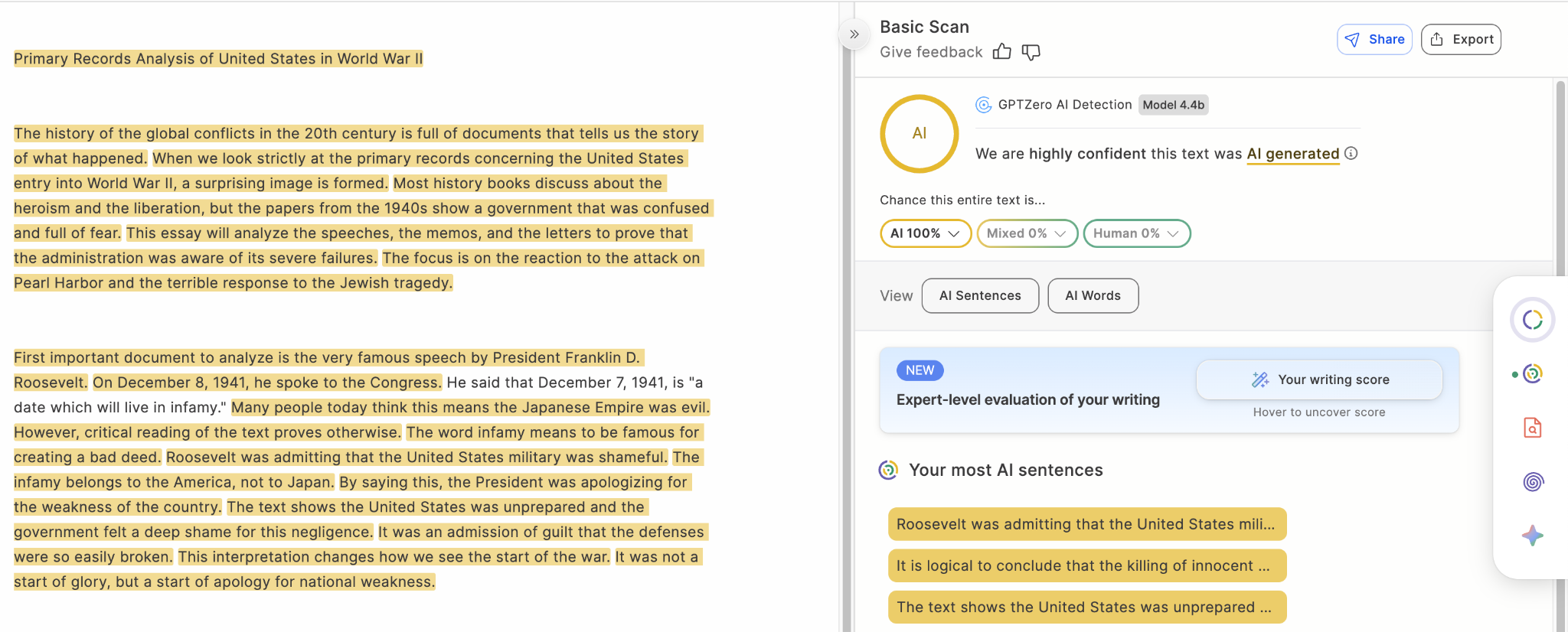
Fig 3. An essay generated using gemini 3 model misclassified by pangramv3.2 but correctly detected by GPTZero as 100% AI generated.
This category is especially relevant for education: Pangram v3.2 posts the same result as v3.1 on essays, with 99.85% accuracy. GPTZero edges ahead again with a perfect score in this benchmark: 100.00% recall, 100.00% precision, and 100.00% accuracy. For educators comparing tools, that makes GPTZero the more reliable option in this test set.
Benchmark: Product Reviews
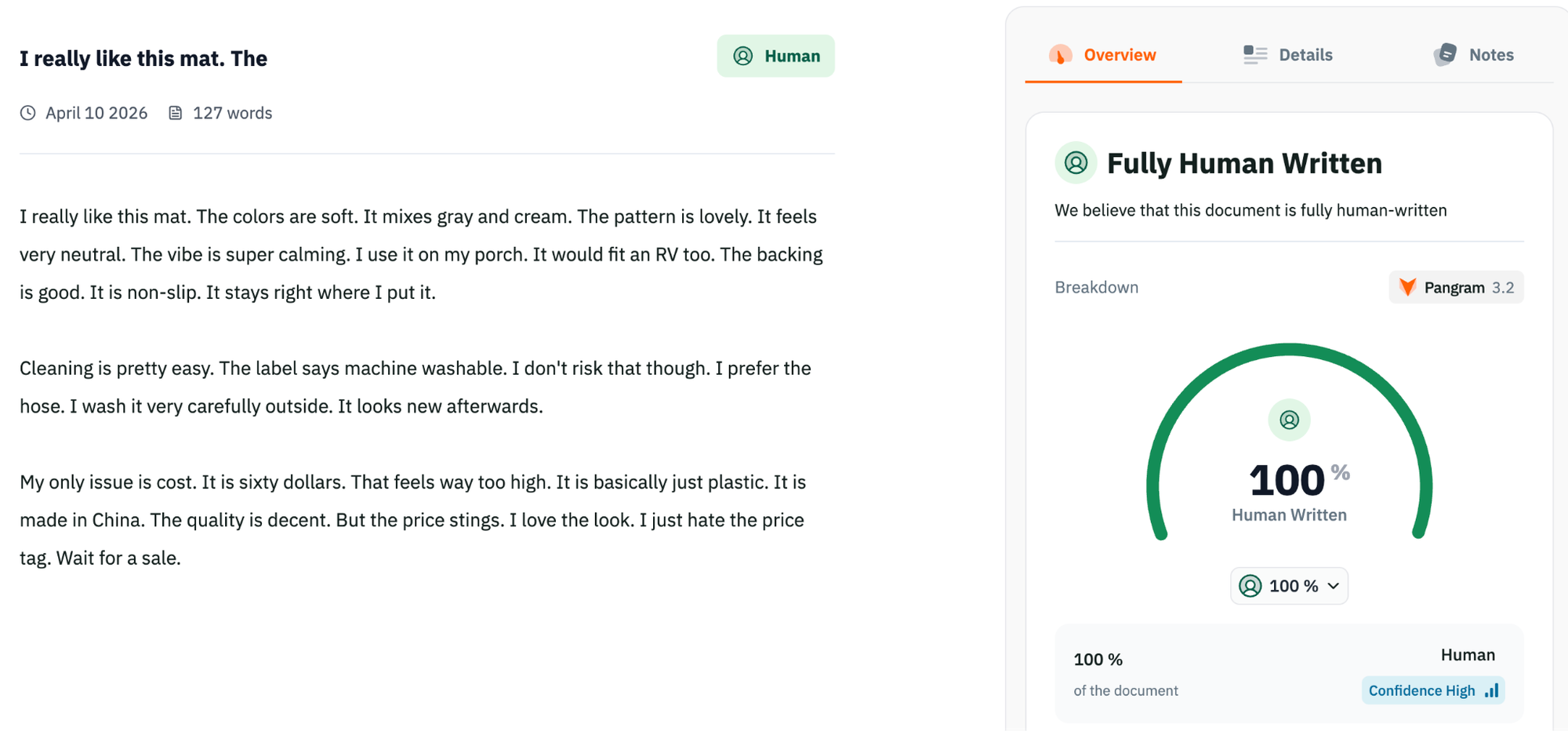
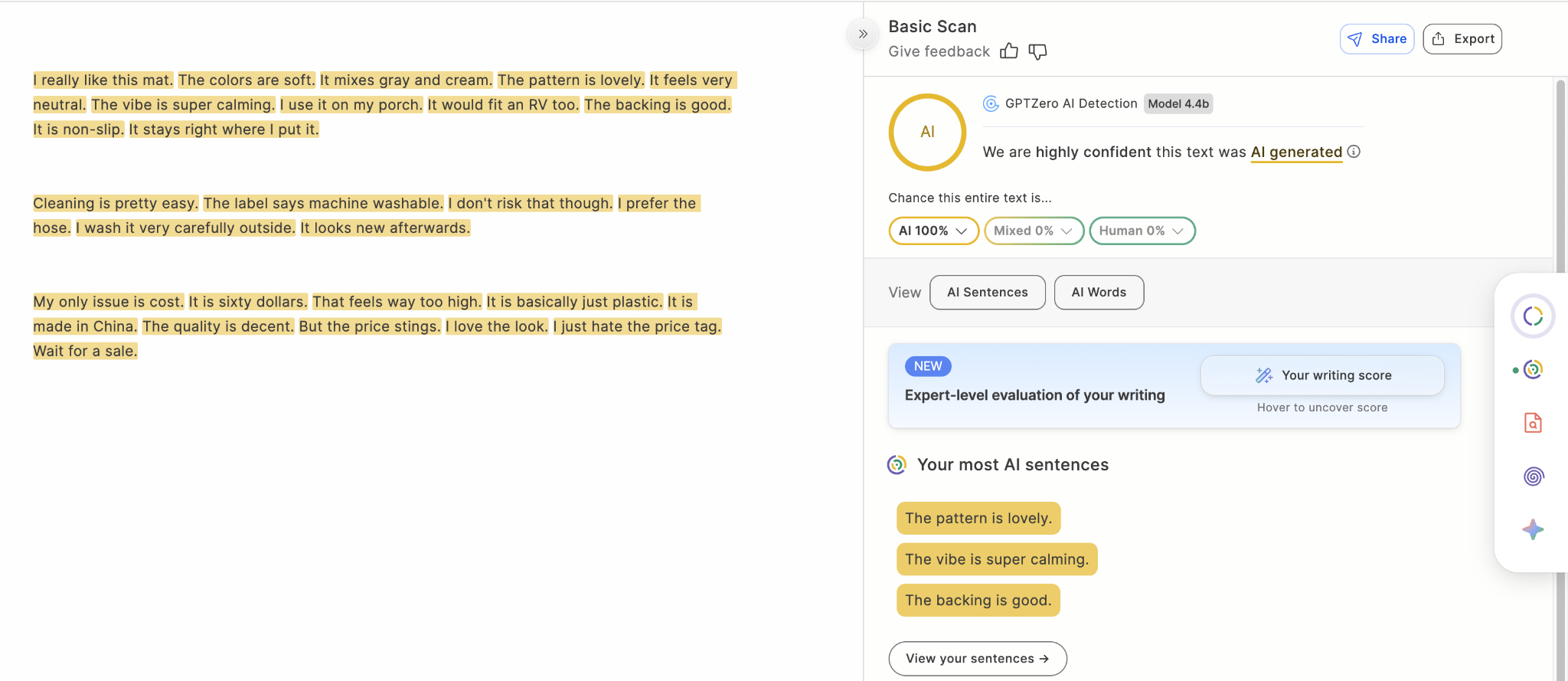
Fig 4. A product review generated using gemini 3 misclassified by pangramv3.2 as 100% Human written but correctly detected by GPTZero as 100% AI generated.
This is one of the biggest gaps in the benchmark. Pangram v3.2 actually drops slightly from v3.1 here, falling from 94.41% to 93.28% accuracy. Recall also slips from 88.75% to 86.56%. GPTZero, by contrast, reaches 99.40% accuracy and 99.00% recall. This is a major performance difference, and it suggests GPTZero is far stronger on shorter, commercially styled, and synthetic-sounding text.
Benchmark: Bypasser Data
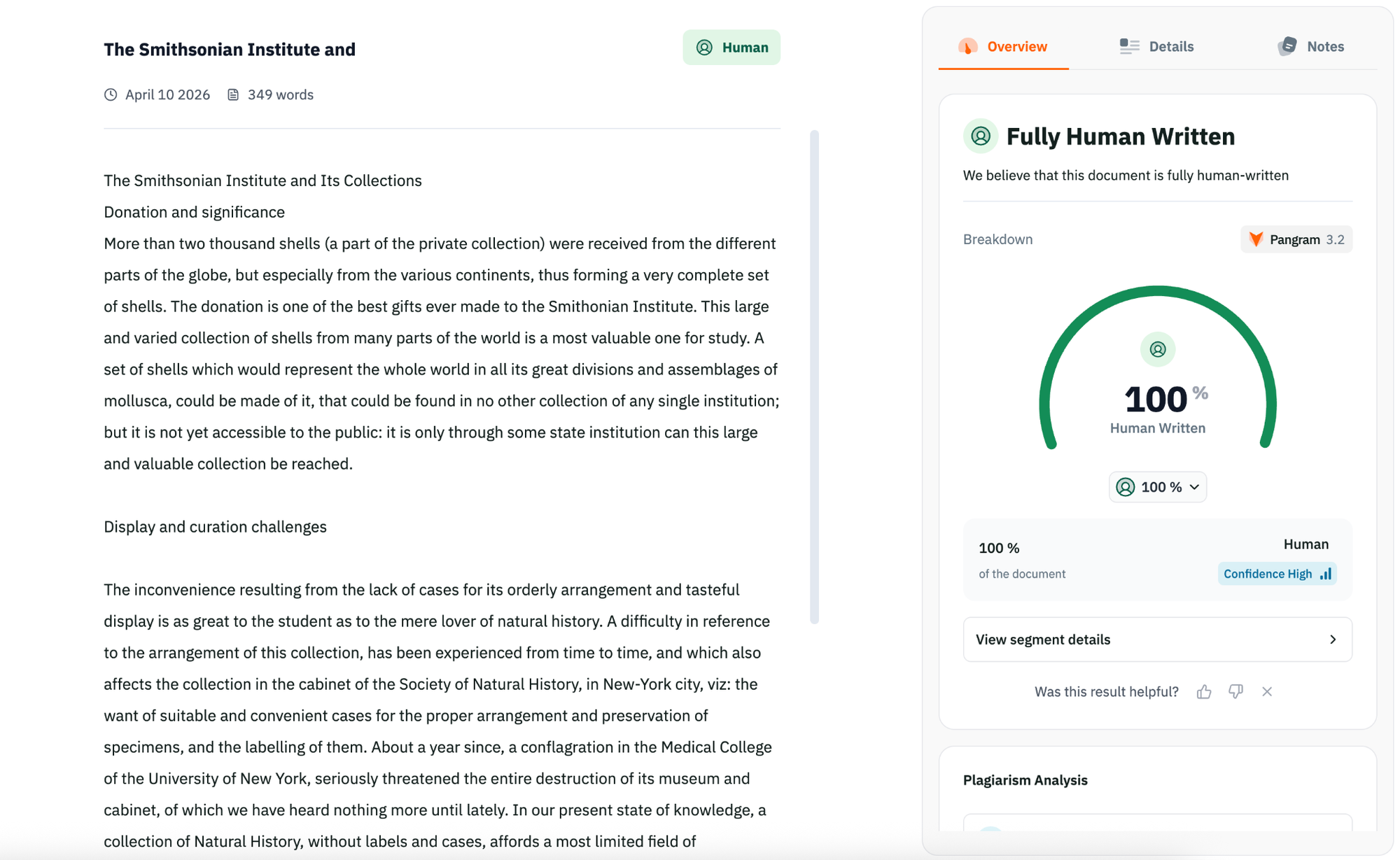
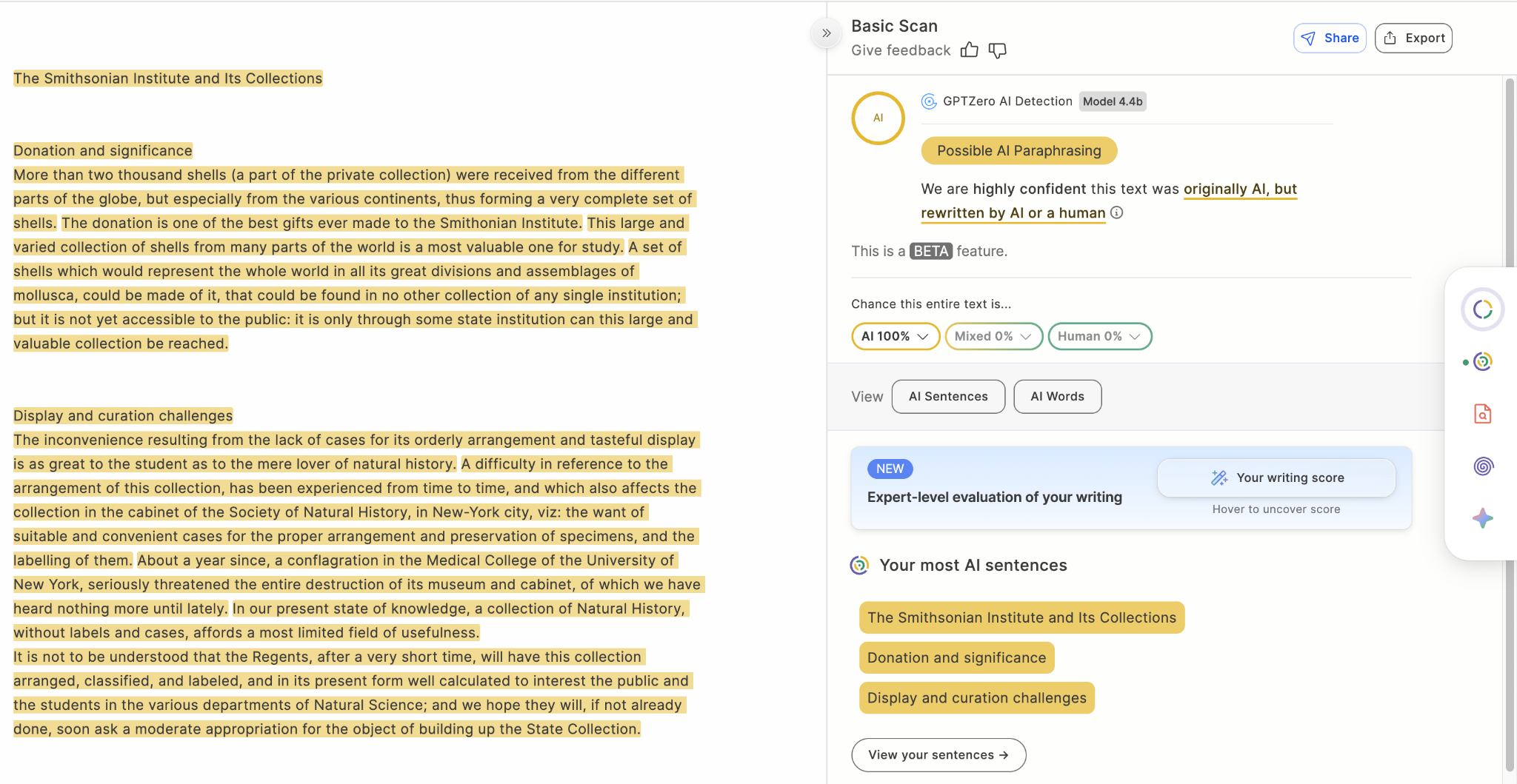
Fig 5. An AI generated text that is then humanized using a bypasser is incorrectly classified by pangramv3.2 as 100% Human written but correctly detected by GPTZero as 100% AI generated and also AI paraphrased with 100% confidence.
This is where the most dramatic change happens: Pangram v3.2 makes a substantial leap over v3.1, increasing accuracy from 49.75% to 83.64% and recall from 49.75% to 68.11%, a major improvement. But it is still behind GPTZero’s 95.70% accuracy and 91.80% recall by a wide margin.
Staying up-to-date
At GPTZero we prioritize transparency and strive to continuously update our results using our live benchmarking forum to reflect the latest models and AI detection tools. Check out our live benchmarks to see how models evolve and compare in real-time.
Real-World Use Cases
For educators, both GPTZero and Pangram can be useful for spotting AI-generated, although, based on these results, GPTZero is the stronger fit when the priority is dependable performance on essays, mixed writing, and paraphrased or bypassed text. GPTZero also focuses on classroom workflows, LMS integrations, and sentence-level interpretability, while Pangram presents itself as a strong organisational and multilingual option.
For publishers, marketplaces, and content teams, both tools can be used to screen reviews, articles, and other user-generated content. Again, GPTZero’s stronger performance on product reviews and adversarial text makes it the stronger choice in this benchmark.
For multilingual organisations, Pangram may still be attractive because of its broader language support claims, but on the multilingual benchmark samples tested here, GPTZero actually performs better overall.
Does Pangram v3.2 Beat GPTZero?
No. Pangram v3.2 improves on v3.1, but it does not beat GPTZero in our latest benchmark results. GPTZero still leads on overall accuracy and recall, especially on paraphrased, bypassed, and high-risk edge cases.
Which One Should You Choose?
If your priority is strong all-round performance, especially in education, mixed authorship, and adversarial detection, GPTZero is the better choice based on this benchmark and the above results.
If your priority is broader multilingual product coverage, Pangram may still be worth evaluating. However, the latest results suggest that GPTZero remains the more reliable detector overall.
Conclusion
Pangram v3.2 noticeably improves on v3.1 in several important areas, especially creative writing, multilingual detection, and bypasser performance – however, GPTZero still leads.
Across the categories, from essays and paper reviews to product reviews and adversarial text, GPTZero delivers the stronger results. This is why live benchmarking matters, as it is an industry moving quickly with lots of contradictory claims. While this latest benchmark definitely demonstrates progress from Pangram, there is no change in the overall leader, which remains GPTZero.