How Independent AI Detection Can Prevent Model Collapse
Why watermarking isn’t enough and AI models need better data labeling to prevent degeneration.

AI large language models like ChatGPT, Gemini, Claude and Llama train on huge amounts of human data—books, articles, documents, videos, and more—to better learn how to reproduce human speech and writing. Early sources estimated OpenAI’s GPT-4 model would use more than 100 trillion parameters. But if you’re a generative AI company that has already ingested and trained on the entire body of readily available human work from the past, getting fresh data has often meant either creating it yourself (with AI), buying data from third parties, or scraping from a post-ChatGPT internet increasingly full of generative AI content. And all these methods come with risks.
From Nature to the New York Times, the risks of training recursively off synthetic data are starting to enter public discourse, and discussions of “model collapse” are on the rise.
Model collapse is when AI-generated outputs become garbled and incomprehensible because the training data is mixed with AI outputs that are less diverse, a problem made worse through repetition.
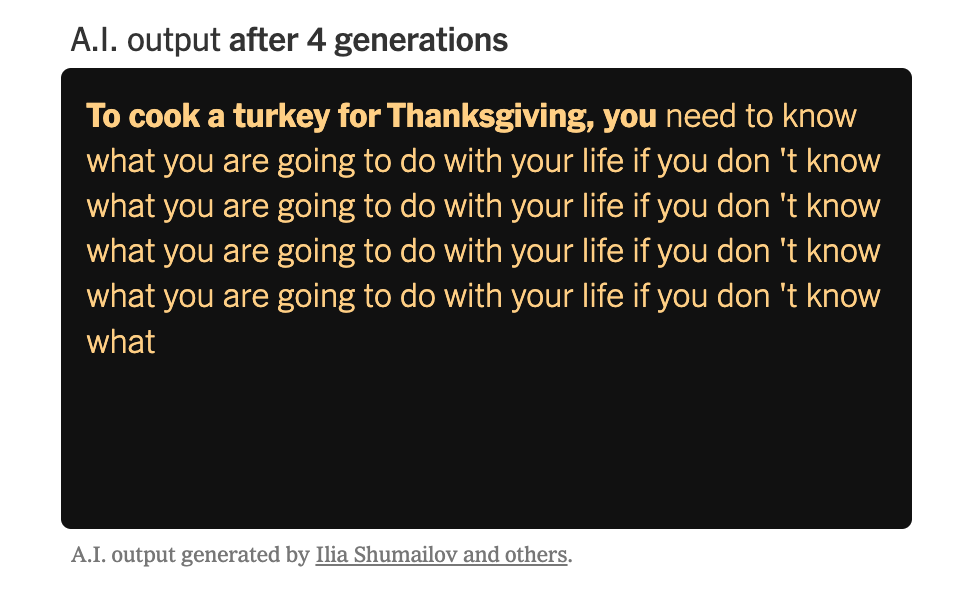
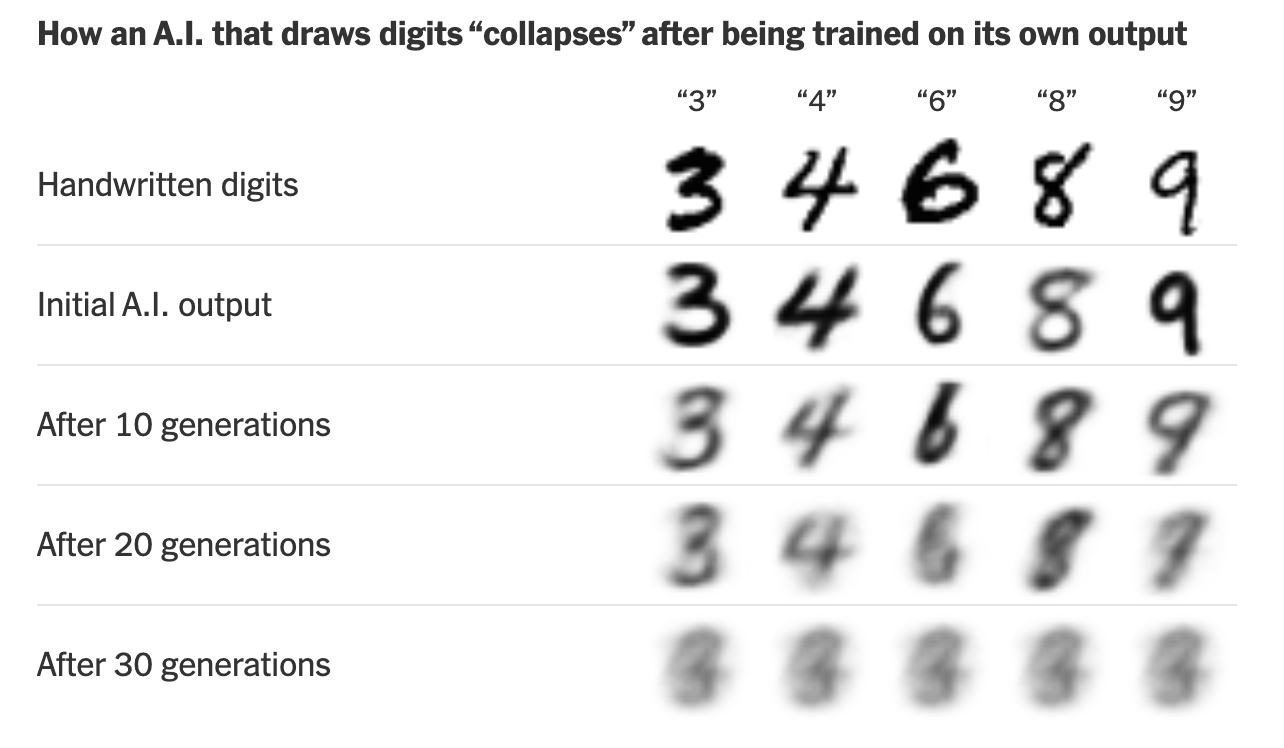
Snippets from the NYT Article "When AI's output is a threat to AI itself," by Aatish Bhatia (Aug 2024), showing the threat of model collapse.
The idea that a model like GPT-4 could collapse entirely sounds like extreme doomsaying, but the reality is that outputs from recursive training already present very visible information quality risks. As the leading AI content detection platform, GPTZero has investigated how AI search engines start replicating fake reviews and websites within a few steps. Any misinformation in those pieces are then replicated and passed off as fact.
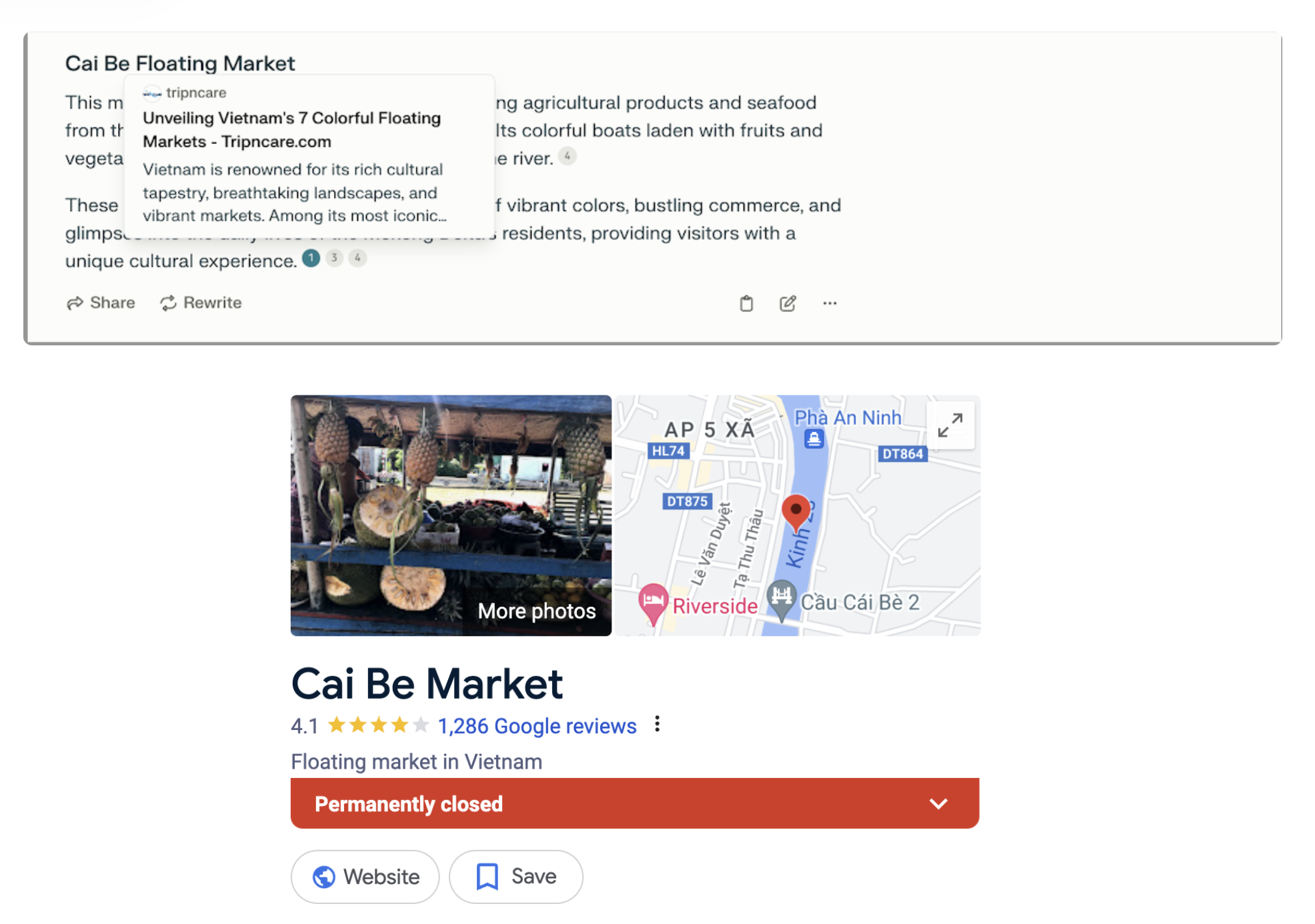
The poor quality of AI-generated outputs could improve over time with new models, but that only happens if we can identify and properly label our data, so we don’t get “garbage in, garbage out.” We’ve seen an increase in demand for GPTZero’s AI detection platform by AI companies for labeling and cleaning their training data.

If left unaddressed, the reputational damage from poor quality outputs poses not just a risk for everyday people using AI, but also the generative AI companies who want to scale and encourage AI adoption. We’re here to explore different solutions to prevent model collapse and share why we believe independent layers of truth are essential to protecting information quality in an AI world.
What is AI watermarking and will it help prevent model collapse?
One popular solution for model collapse prevention is for AI companies to create some form of way to label their own content, known as “watermarking.” Headlines reported that OpenAI has explored ways to detect its own content, but are hesitant to release a feature even when calls from concerned journalists, educators, and technological ethicists have expressed demand for it.

From our experience working in AI detection, we believe that watermarking has a number of limitations including:
- Watermarking doesn’t work great when models are translated from one model to another; for instance, someone can run a script from ChatGPT into another model or AI paraphraser. An AI model developer can only build detectors for their own watermark.
- People have already demonstrated how to bypass watermarking with various attacks.
- Motivation: OpenAI’s decision to not release a way to detect ChatGPT reflects the conflict of interest within AI companies; companies that stand to benefit from more AI content don’t necessarily want to release tools that make their content easily distinguishable (even at the risk of future model collapse).
Especially for these reasons, well-intentioned legislation like the California AI Transparency Act that require AI companies to build their own detection may help develop a healthier space for consumers, but independent detection will always be important for foundational models to make sure they can monitor the health and quality of their inputs.
How to use independent AI detection as a data labeler and LLM engineer

Generative AI companies who take seriously the risks of training off recursively generated data should go to great lengths to find training data from real humans, whether through purchasing access to existing data sets or working to create new ones.
People have started paying larger data labelers for expert text that they think is human. But one study showed that 33-46% of these human sources are actually using AI instead to get their job done faster. Companies like Scale AI have tried to crack down on the issue by restricting their data to wealthier, English speaking countries. But as freelancers around the world increasingly use AI tools, there’s no guarantee that a data set created after 2022 (when AI was made readily available to the general public through ChatGPT) isn’t contaminated by AI inputs—unless you invest in some form of detection at the training level.
Companies can use GPTZero's API to ensure data created from their data labelers are free of any third-party LLM usage, cleaning any AI generated text from their human training data. Our API clients have found that their AI models trained without synthetic data provided longer, high quality responses, with better adherence to prompts and less hallucination. When running internal tests on how GPTZero’s AI detection affects AI training data, we’ve seen at least a 5% improvement on key benchmarks like massive multitask language understanding (MMLU).
Some more things that GPTZero is able to offer LLM engineers and data labelers:
- Scale: We can handle millions of scans per day with an average 0.4s for a 700 word document for our public REST API.
- Multi-model detection: We constantly update to detect the latest model releases from ChatGPT, Gemini, Claude, Llama, and smaller, domain-specific models like AI paraphrasers and detection bypassers.
- Interpretability: GPTZero gives more than just binary classifications of “AI vs. human” for a data set; our premium model combines recent breakthroughs in AI detection to offer granular details down to the sentence or phrase and probability.
- Customization: GPTZero’s machine learning team has custom trained models for enterprise clients tailored toward specific use cases, from detecting online reviews to data labeling freelance submissions.
- Security: We offer on-premises API options and SOC 2 Type II compliance for our platform to handle enterprise use cases.
But even though a large LLM company can invest its own resources into building detection, we believe it is important to have an independent layer of AI detection for all models available. GPTZero’s mission is to preserve informational quality and transparency; in doing so, we can prevent the degenerative risks of synthetic data and stave off model collapse.
If you’re interested in learning more about using GPTZero’s detection for your AI datasets, you can see our pricing for our API.


