Understanding AI Detection Results with Deep Analysis

The GPTZero team is committed to machine learning interpretability as a core aspect of our mission of preserving human value. In a significant step towards this goal, we released our Deep Analysis feature this week for premium users (shown in Figure 1).

Users are able to activate this feature by enabling the Deep Analysis switch on the dashboard when scanning a document. This view provides a novel perspective into how our models reason about a given document to determine whether or not it was written by AI. Sentences are highlighted according to whether they contribute to the model predicting human vs. AI, with green and orange suggesting that a sentence makes our model believe that the document is more human or AI respectively. Highlight intensity indicates how much a given sentence affects the overall prediction.
Interpretable model predictions play an important role in enabling users to better understand and trust what would otherwise be a black-box algorithm.
For example, no machine learning model is perfect, so if a model makes an erroneous prediction, users benefit from knowing why that was the case so that they are aware of specific model limitations. This also enables higher-quality feedback from users to model developers such that improvements can be made to address these limitations over time.
Conversely, even when a model makes correct predictions, it is advantageous to know that it did so for the right reasons, and did not rely on some spurious feature that happens to correlate with the label of interest in limited documents.
If an AI detector relies solely on “Absolutely, here is an essay on…” to determine if a document is AI generated, this will not generalize well to other documents. Additionally, while LLMs like GPT4 often create responses with such prefixes, it is not necessarily the case that genuine human text should be classified as AI just for having one such phrase.
The technical advancement enabling interpretability for our detector's predictions is our in-house Deep Analysis importance values. At a high level, these importance values indicate on average how much a given sentence contributes to our model’s prediction. In some cases, removing/modifying a sentence that has a high importance score for the AI prediction (orange highlighting) will reduce the overall predicted probability of AI for that document. However, this will not always be the case because our model processes documents in a holistic manner, and focuses more on overall document style, structure, and content. Thus, even when a highly AI-like sentence is removed from a document, other sentences fill the void in terms of what is important to the model in making its determination. This robustness to small modifications is a positive attribute for a model to have, although it sometimes makes for less intuitive importance scores.
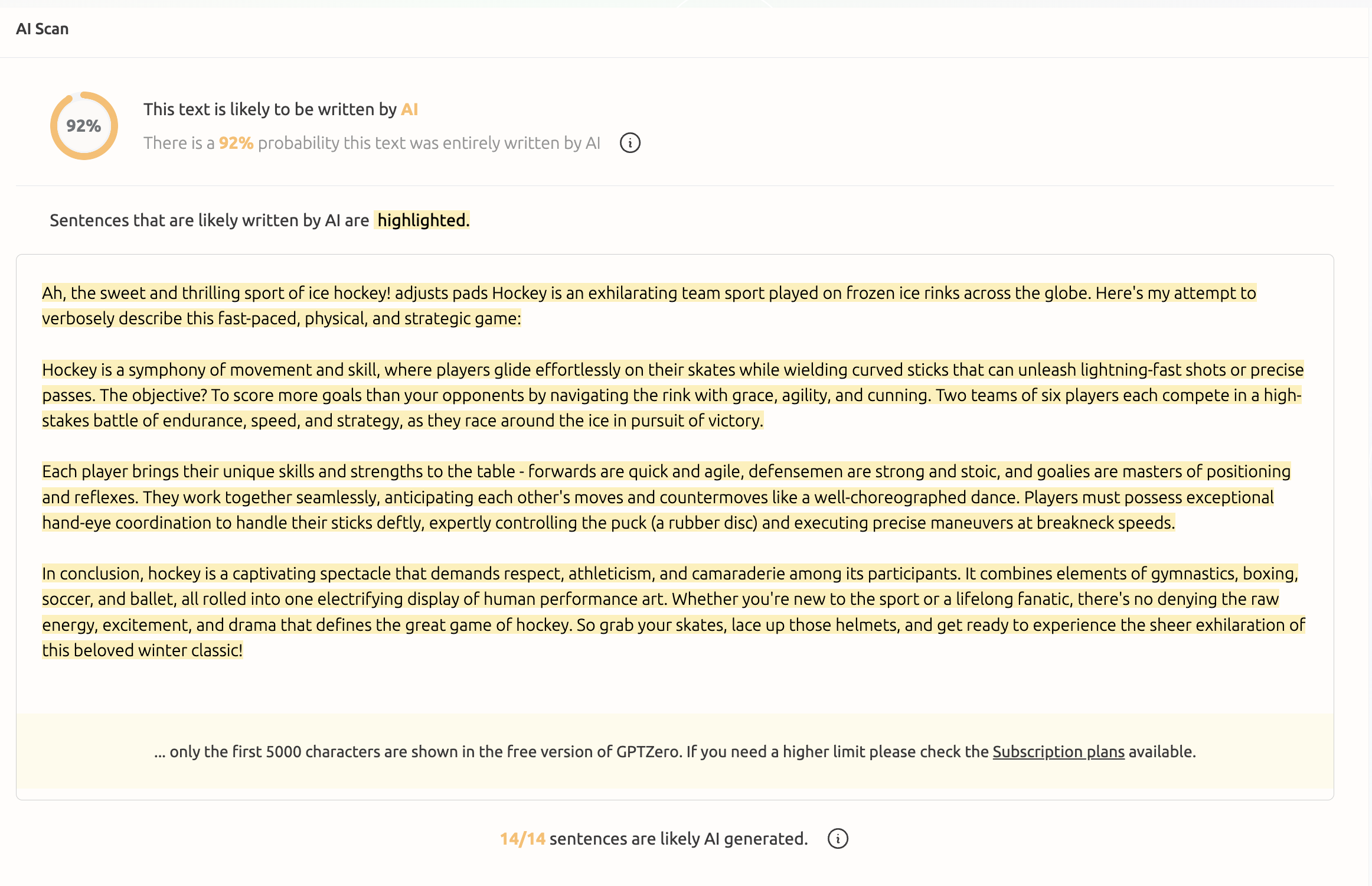
A closer look at the Deep Analysis feature reveals that the top 5 sentences contributing to human or AI prediction are conveniently sorted to help the user get a quick understanding of the most important sentences in the document from the perspective of our model (bottom of Figure 1). This empowers educators to focus on particular parts of the text when making a determination about the genuine origin of an assignment, and ask questions such as: does this sentence sound like something this student typically writes? It also empowers writers to improve their writing and unleash their creativity in sections of their document that they may have otherwise sped through which resulted in generic-sounding content. We note that Deep Analysis differs considerably from typical sentence-level highlighting (Figure 2) which only indicates that our model believes a sentence to be AI-like, but does not analyze how sentences interact to form the final prediction. Importantly, there need not be a perfect correlation between the Deep Analysis highlighting and the sentence-level AI highlighting since they are fundamentally different concepts.
To conclude, Deep Analysis importance scores are not perfect, and for the large models we use at GPTZero, approximations have to be made. We do not intend for this feature to be used to punish students by picking out specific passages that are most AI-like. Instead, Deep Analysis importance scores are to be treated as any other feature that GPTZero provides: an additional magnifying glass in the compendium of an adept editor who uses their judgment along with GPTZero to make an initial impression as to whether deeper investigation of a student’s work is required. Responsible AI use is one of our core tenets, and we strongly believe that the steps we’re taking towards transparency in AI detection empower our users to leverage predictions responsibly.

