Perplexity, burstiness, and statistical AI detection
In January, we released GPTZero’s first AI detection model publicly for everyone. The demand was deafening — with seven million views and half million users in the first week, GPTZero was called Hero of the Week on UK radio, internationally covered, in Japan, France, Australia and over thirty countries, even landing a feature on the front page of the NYT.
The thesis was simple — build a model that is efficient and effective, and make it accessible to every person who needs it. To do so, the original GPTZero model applied a ‘statistical approach’, leveraging academic research in natural language processing to convert written words to numbers for calculation.
Today, the first principles from GPTZero’s original detection model is still being applied widely. These methods are efficient — leveraging numerical analysis instead of deep text analysis. They are the least computationally expensive of AI detection methods. Additionally, they are actually the main applications behind dozens of other AI detector apps including ZeroGPT, Copyleaks, Originality, and Writer[dot]AI. They remain effective — and as such act as one of the seven ‘indicators’ of the upgraded GPTZero detection model, alongside our novel text search and deep learning detection approaches.
What is Perplexity and Burstiness
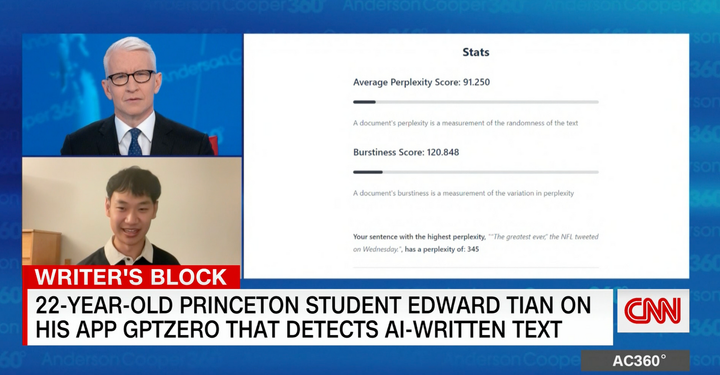
The statistical layer of GPTZero’s AI detection model is composed of a ‘perplexity’ and ‘burstiness’ calculation — together they form the first layer for GPTZero’s AI detection.
You can interpret the perplexities per sentence as a measure of how likely an AI model would have chosen the exact same set of words as found in the document. One aspect of GPTZero’s algorithm uses an AI model similar to language models like ChatGPT to measure the perplexity of the given document.
We’ve trained the AI model to identify when the input text looks very similar to something written by a language model. For example, the sentence, “Hi there, I am an AI _” would most likely be continued by an AI model with the word “assistant”, which would have low perplexity. On the other hand, if the next word that followed was “potato”, then that sentence would have much higher perplexity, and also a greater likelihood of being written by a human. Over the course of hundreds of words, these probabilities compound to give us a clear picture of the origin of this document. There isn’t an absolute scale for perplexity, but generally, a perplexity above 85 is more likely than not from a human source. Here’s a guide with more technical definitions of this measure:
Burstiness, on the other hand, is a measure of how much writing patterns and text perplexities vary over the entire document. As humans, we have a tendency to vary our writing patterns. Philosophically, our short-term memory activates, and dissuades us from writing similar things twice. Conversely, language models have a significant ‘AI-print’ where they write with a very consistent level of AI-likeness. While a person could easily write an AI-like sentence by accident, people tend to vary their sentence construction and diction throughout a document.
On the other hand, models formulaically use the same rule to choose the next word in the sentence, leading to low burstiness. Compared to other statistical methods for AI detection, burstiness is a key factor unique to GPTZero detector, allowing our models to evaluate long-term-context, and perform better with additional inputs.


