How the Best AI Detector Provides Interpretable Scores
TLDR: For a brief summary of this post, please see our support page.
Being innovative often requires challenging orthodoxy and thinking from first principles. But what does this process mean in the context of a domain as young as AI text detection? Although the approaches used for detecting AI text are evolving, there is a baked-in assumption in the output of most detectors that a piece of text is either written by a human or an AI, but not both. This false dichotomy makes sense primarily in scenarios where writers copy and paste the output of a large language model (LLM) like ChatGPT without making any modifications to it. Many writers follow more sophisticated workflows than this. For example, a writer might produce half a document themselves while the rest is completed by an LLM. It does not make sense to force a detector to output one of AI or human in such a scenario. Instead, the detector should indicate that the document is a mix of human and AI text, while sentence highlighting indicates which sentences are likely to have been generated by AI. In addition to being more representative of real-world inputs, categorizing predictions this way enables the confidence of the detector to be disentangled from the percentage of sentences that are AI-generated. Without this distinction, an AI probability of 50% could mean that the detector is 50% confident in its prediction (essentially a coin flip), or that 50% of the text is AI-generated.
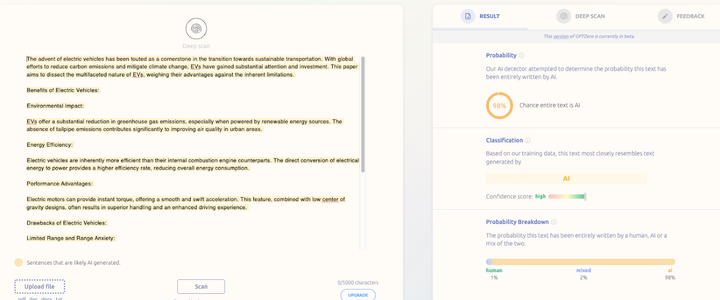
Our most recent model update currently being rolled out leaves the false dichotomy of AI detection in the past. Figure 1 shows the new outputs per class for an example AI-generated document on our website. Here is a breakdown of the results
- The Probability section focuses on the probability that the article was entirely AI-generated, which in this case is 98%
- The Classification section then indicates that if our detector had to choose between one of the 3 options of AI, human, or mixed, it would choose AI for this document
- The Probability Breakdown section then reveals the model probabilities across all 3 classes
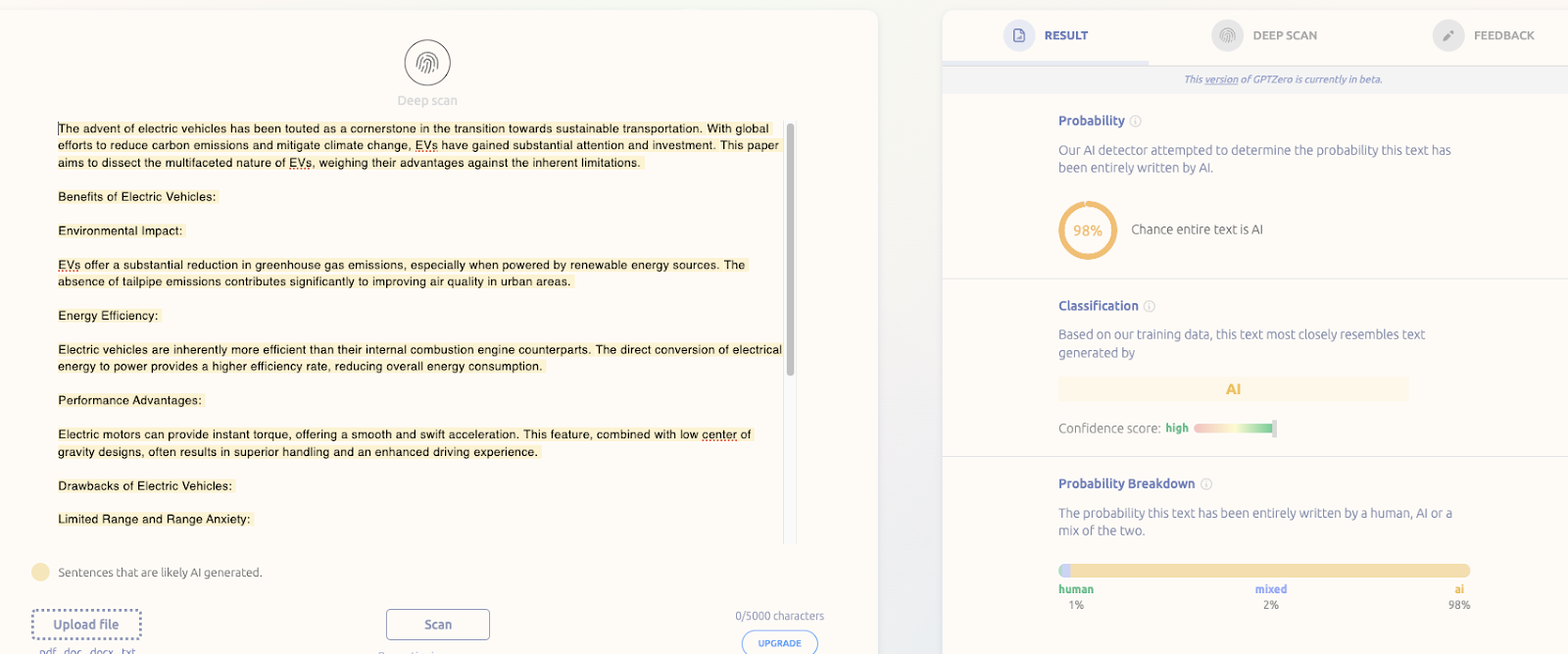
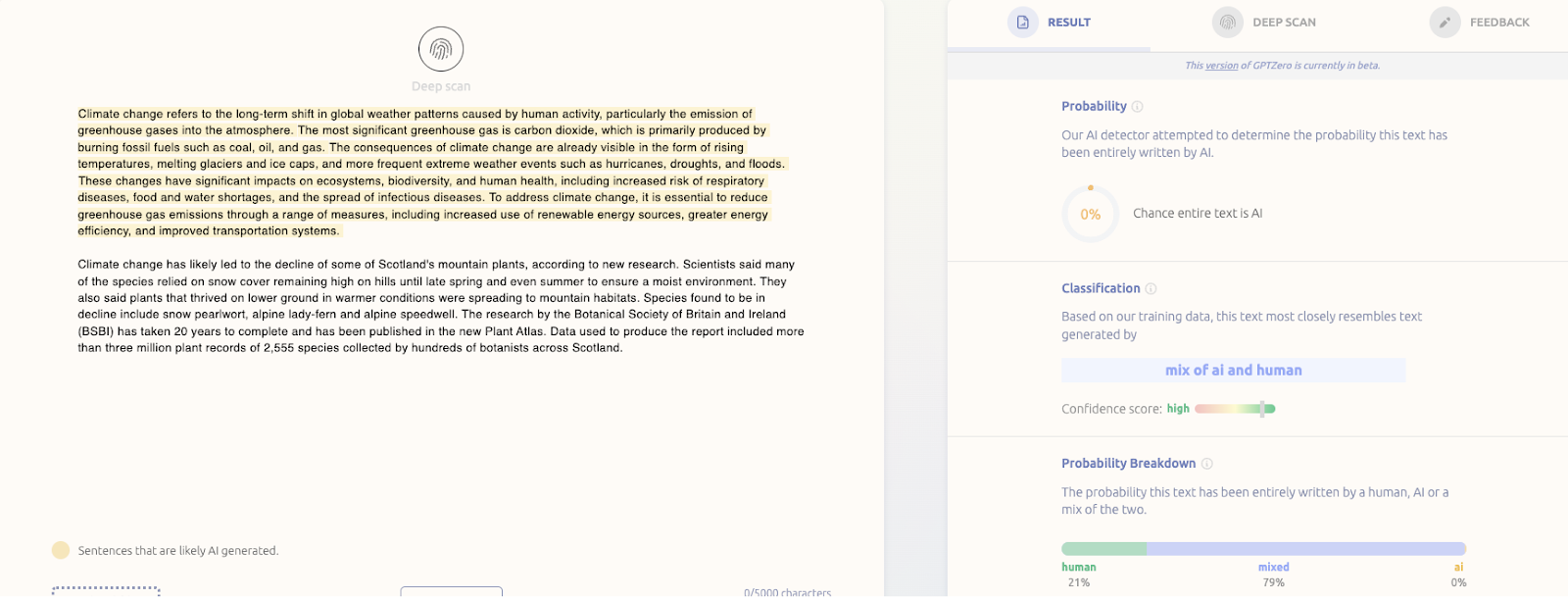
Now for the example on our website that is a combination of human and AI text, Figure 2 reveals that the mixed class now has the highest probability of all 3 classes at 79%, while the classification has been changed to “mix of ai and human”. The highlighting shows the particular sentences which are likely to be AI-generated. Interpreting a number like 98% or 78% is not trivial and requires a discussion about calibration.
Even the most accurate machine learning models make errors, and while GPTZero strives to be the best AI detector available, occasionally our detector is wrong. What’s important in these cases is for users to properly interpret the predicted score. In an ideal scenario, a predicted probability of 79% means that on documents that have similar predictions, the detector is correct 79% of the time. Our most recent model update uses a post-hoc calibration step to ensure that for the most part, our detector is not overconfident in its predictions. While this improves calibration significantly, achieving perfect calibration is nearly impossible. Also, 79% is a value that is missing context, and may still be difficult for a user to interpret. To aid in this interpretation, we now also provide a confidence score which falls into 3 categories of “low”, “medium”, and “high”. The categories are tuned so that the average error rate is less than 1% for the “high” confidence predictions, based on a diverse evaluation dataset used internally, that was never before seen by the model. Average error rate is emphasized because the number of possible documents is vast, varying substantially in tone, content, length, grammatical correctness, logical coherence, and structure. There are combinations of these attributes that may result in significantly lower error rates than 1% at high confidence, while others have a slightly higher error rate. Thus, while it is unlikely for our detector to be incorrect when it makes a high-confidence prediction, especially when predicting high probability values > 98%, we do not encourage punitive actions based solely on the results of a single scan. Instead, a history of scan results should ideally be established, serving as stronger evidence of AI usage.
Our team at GPTZero continues to push the boundaries of what’s possible in the realm of detecting AI. Optimizing the fluency of the human-computer interaction which occurs whenever predictions are interpreted is no less important than optimizing the quality of the detector itself. By switching to a new UI that better represents the underlying reality of how a document is composed, detector outputs have a more natural interpretation in terms of the likelihood of being correct, and users are more likely to make responsible decisions based on scan results.


