GPTZero Tops Accuracy on Chicago Booth Benchmark in 2026
GPTZero outperforms other AI detectors like Pangram on Chicago Booth Benchmark, achieving ~99% accuracy and industry-leading recall for AI detection.
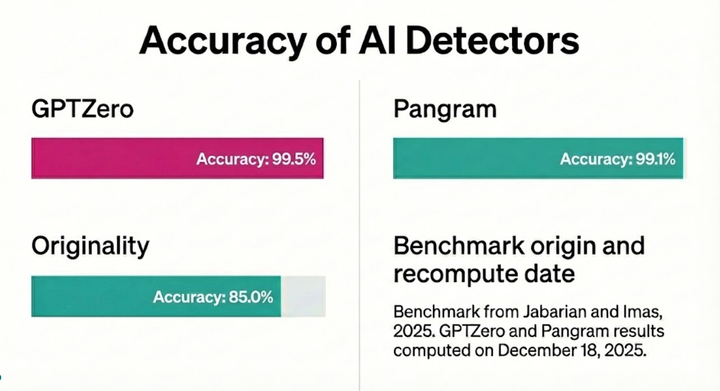
When benchmarking AI detectors, it’s important to reflect the truth. On August 26, 2025 researchers from the University of Chicago - Booth School of Business published an independent academic benchmark comparing performance across leading commercial AI detectors. While our model did well, we noticed the researchers did not use the correct field in our API for the AI probability. We’ve re-evaluated our AI detector on this benchmark for 2026, and found that GPTZero is still the leading choice for AI detection, surpassing Pangram, Originality.ai and open source models in accuracy.
AI Detection Results
Table 1 shows the overall detector results using three standard metrics: false positive rate (FPR), recall, and accuracy. All detectors show strong performance with ~0.1% FPR, meaning only 1 in 1000 human documents are misclassified as AI.
However, GPTZero achieves 99.3% recall, meaning it identifies nearly all AI-generated documents in the dataset. This is 40% fewer errors than Pangram and 95% fewer errors than Originality. A table with predictions from all 3 detectors evaluated can be found here.
Table 1: Overall AI detector classification performance
*Note that only 6879/9960 predictions were processed for OriginalityAI.
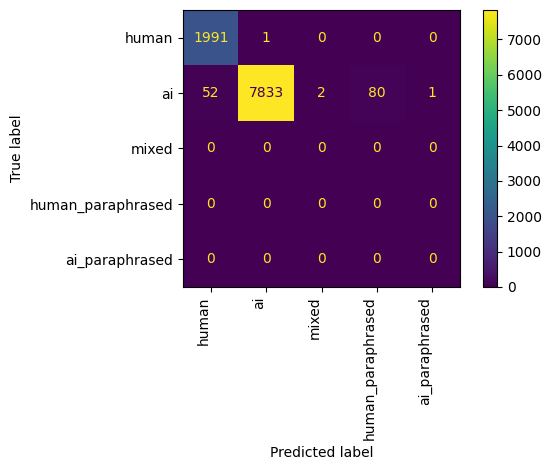
Figure 1 shows our AI detection results as a confusion matrix. This analysis was run with version 2025-12-18-base of our AI detection model.
Dataset
The dataset the authors compiled includes 1992 human texts sampled from publicly available review, blog, news article, and novel excerpts. While we do train on datasets from each of these domains, we haven’t explicitly trained on this dataset.
Each human document was paired with an AI-generated version created using GPT4.1, Claude Opus 4, Claude Sonnet 4, and Gemini 2.0 Flash. The models were prompted to write on the same topic and with the same target word count, to allow a controlled comparison.
How to properly Interpret GPTZero’s API results
In the research paper, the authors compare performance at different thresholds from the following fields returned by the detector APIs:
- GPTZero: average_generated_prob
- Pangram: prob_ai
- OriginalityAI: probability_ai
It’s important to note here that the average_generated_prob field from the GPTZero API is the average of sentence-level AI probability, and should not be used for binary classification. Unfortunately, the authors did not reach out to GPTZero about this. The class_probabilities field is the class probability breakdown of the document, which follows the traditional definition of AI probability. For assessment of classification performance on documents, class_probabilities should be used. You can see the API response details and definitions in our documentation.
In table 1 we report metrics based on the predicted class, which we have found to be the most relevant information for users. In our experience, dashboard users see the predicted class before diving further into class probabilities, AI vocabulary, and Natural Language Explanation, so this largely forms users’ opinions about whether a document was human-written or AI generated.
We use the following classification fields:
- GPTZero: predicted_class
- Pangram: prediction
- OriginalityAI: classification
GPTZero’s multiclass classification
Unlike binary-only detectors, GPTZero offers five classification labels, helping users understand the varying use of AI in the writing process.
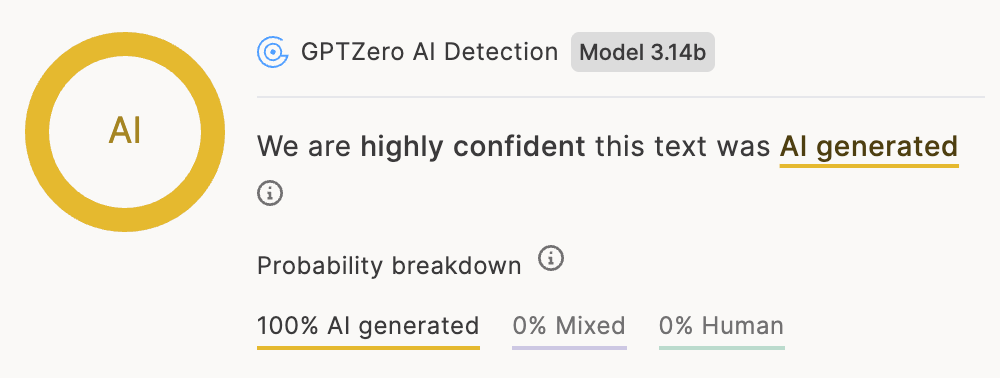
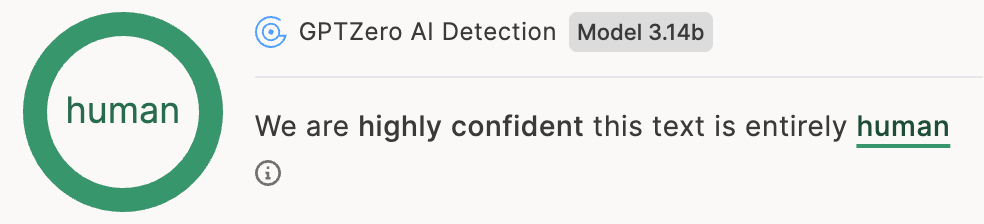
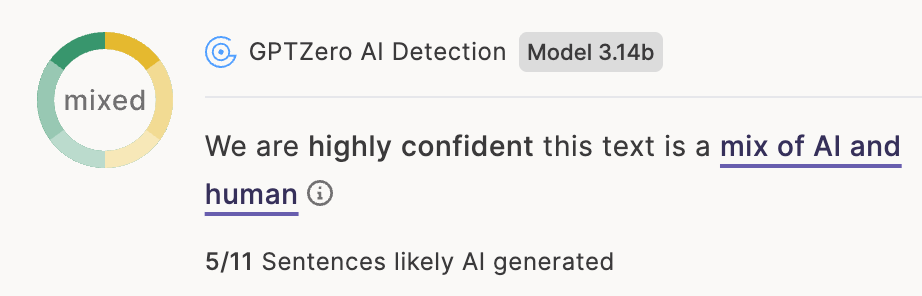
Our unique AI paraphrased (ai_paraphrased) and Lightly edited by AI (human_paraphrased) subclasses:
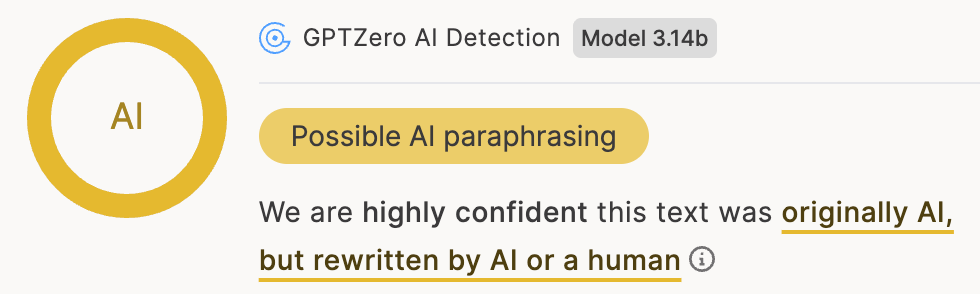
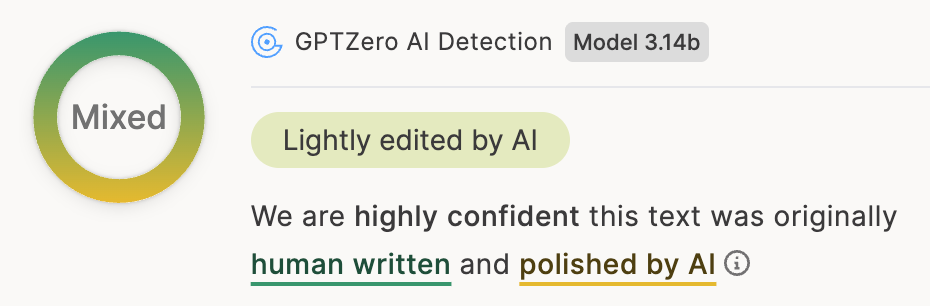
Defining binary classification
The Pangram API returned a classification of Unlikely AI, Possibly AI, Likely AI, or Highly Likely AI at the time the dataset was collected. OriginalityAI returned “AI” or “Original”. For the purposes of reporting binary classification metrics in table 1, we report each detector’s classification performance with the following rules:
- GPTZero
- AI: AI, AI-paraphrased, Mixed, Lightly edited by AI
- Human: Human
- Pangram
- AI: Highly Likely AI, Likely AI, Possibly AI
- Human: Unlikely AI
- OriginalityAI
- AI: AI
- Human: Original
What this means for you as a GPTZero user
For dashboard users, the most important takeaway is that the latest version of our detector has over 99% accuracy on this academic benchmark. While all of the detectors that were analyzed have low false positive rates, GPTZero has the best recall, and therefore the highest probability of detecting AI documents and best accuracy.
In order for API users to see the same results as in our dashboard, they should use the following fields:
- class_probabilities for understanding document probabilities
- predicted_class for multiclass classification.
Both the dashboard and API always use our latest model version, so you can expect consistent and highly accurate results, regardless of how you access GPTZero.


