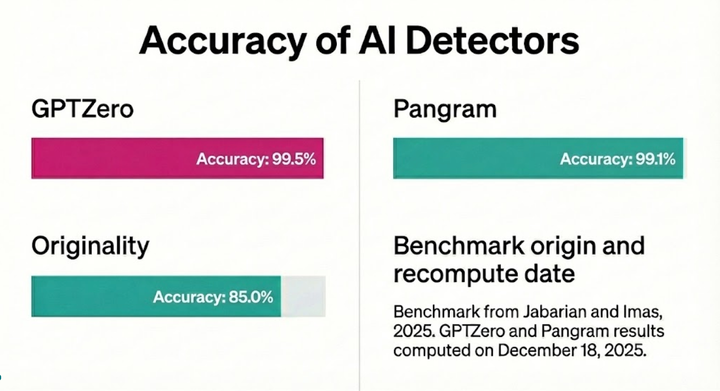
How does GPTZero's Hallucination Check detector work: A technical report

Introduction
Hallucinated citations are one of the most frustrating failure modes of Large Language Models (LLMs). While some "vibe citations" are easy for humans to spot, most seem plausible on first glance and require high levels of technical expertise or time-intensive research to identify. Additionally, the production of LLM-generated text (and vibe citations) has scaled explosively since 2022, outstripping the growth of human expertise and research capacity. This disparity has placed an untenable burden on the finite pool of human experts tasked with reviewing scholarly and scientific work, as well as teachers, researchers, lawyers, and other professionals in citation-intensive fields.
Hallucination Check is GPTZero's answer to the problem of vibe citing. It rests on three design choices: (1) a formal taxonomy of citation failure modes which removes ambiguity by clearly defining a hallucinated citation; (2) exhaustive sourcing against a local database, external citation APIs, and an internet-scale retrieval pipeline; and (3) LLM-based reasoning as a fallback for cases where programmatic matching is inconclusive.
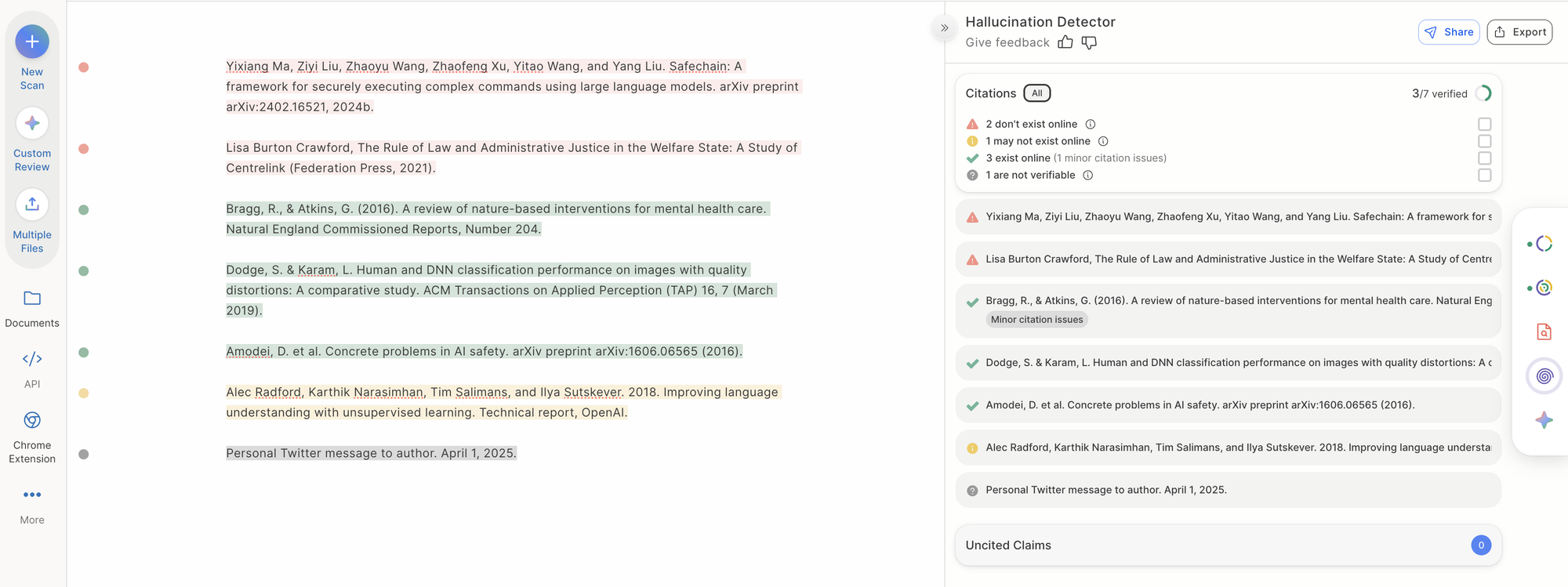
Hallucination Check provides a card for each citation that includes the final class, the most similar source found, the citation-source similarity at a component level, and a natural-language justification for the classification.
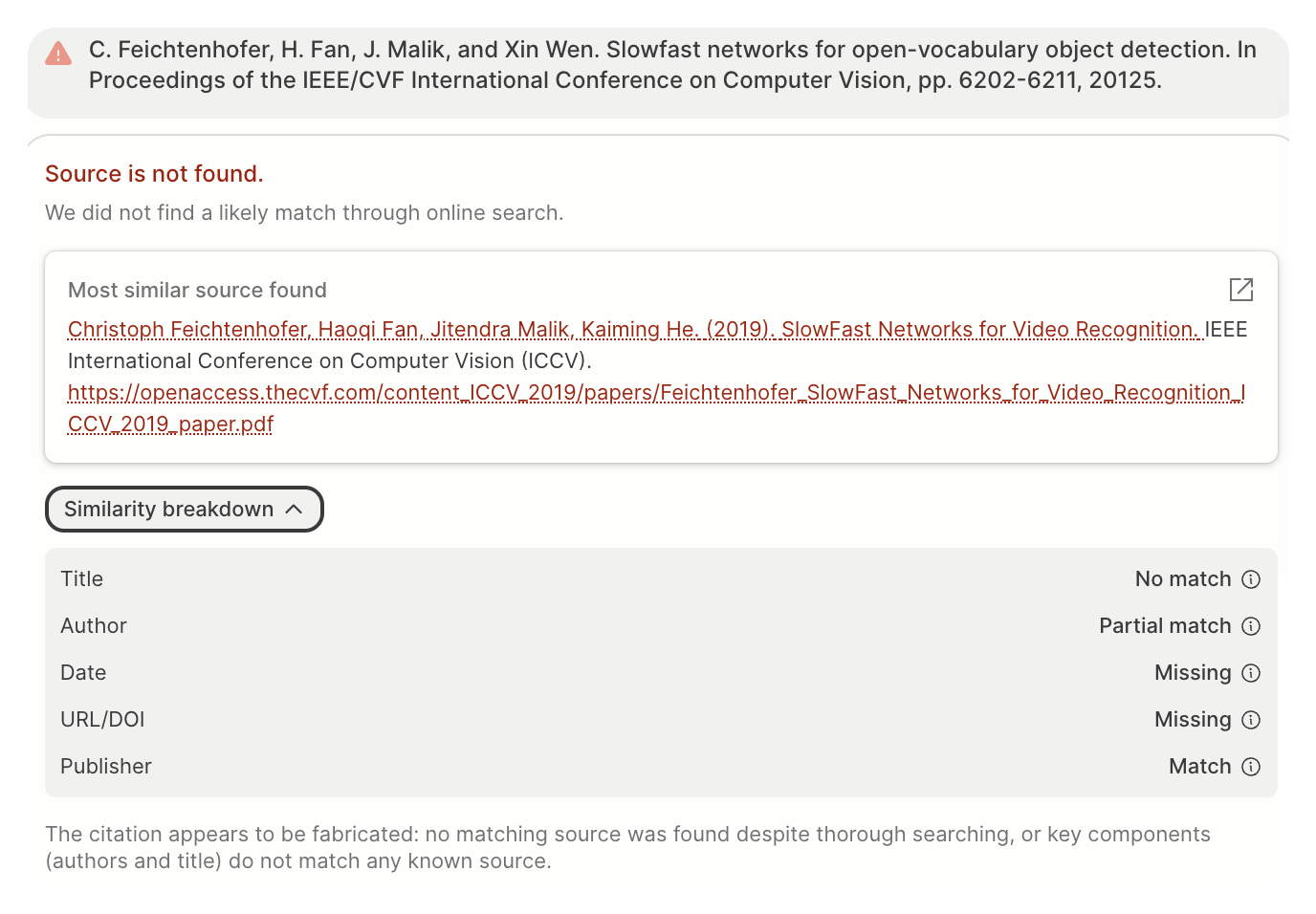
GPTZero is aware of the potential consequences of a false positive for authors, researchers, and academics. Hallucination Check mitigates this risk in two ways: a multi-step retrieval pipeline that maximizes the chance of locating a cited source (when one exists), and a taxonomy sensitive to error patterns characteristic of AI-generated citations rather than ordinary human mistakes. Even so, Hallucination Check obviously cannot guarantee that a flagged citation is an AI-generated hallucination. The scan provides evidence; it is not an oracle.
Method
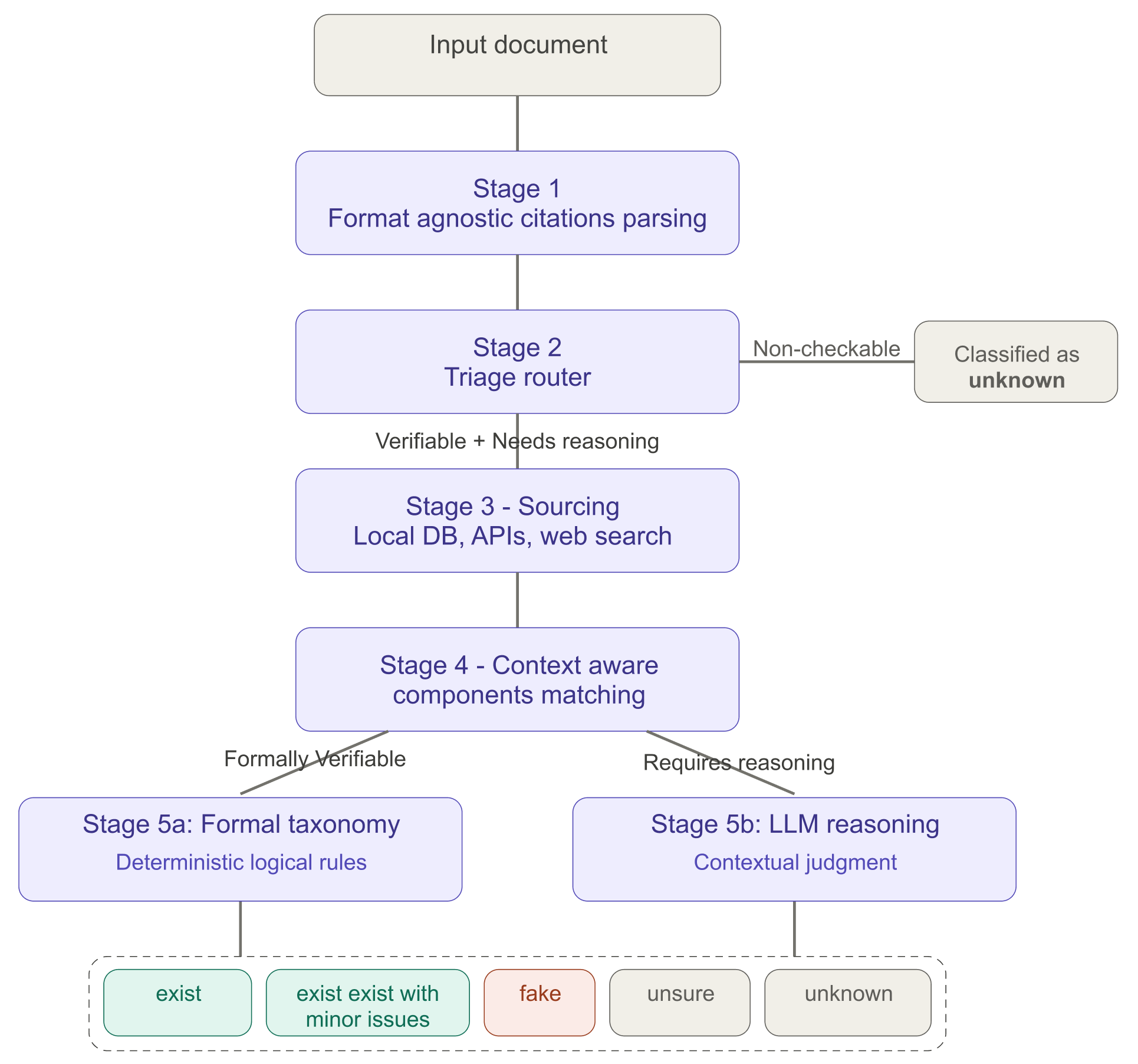
Stage 1 - Citation Detection & Parsing
The first stage of the pipeline identifies citations within a document and parses each into a structured representation. The system accepts any common document format, including raw text, PDF, and Word docs. A dedicated PDF parsing pipeline handles the complexities of PDF-specific formatting, including footnote extraction and hyperlinked text resolution. For scanned or image-based documents, optical character recognition is performed using a cloud OCR API.
Stage 2 - Triage routing
The system performs initial citation triage, routing each parsed citation into one of three paths:
- Formally verifiable: Citations that include structured bibliographic components such as authors and title. Common examples include citations for journal articles, books, conference papers, and similar scholarly references.
- Requires reasoning: Citations that lack formal structure or/and refer to well-known or canonical sources (e.g., the Bible, widely recognized databases) or other references where verification requires semantic reasoning rather than component-level matching.
- Non-checkable: Citations that cannot be verified by design — for example, "Ibid," unpublished manuscripts, private correspondence, or sources that haven't been digitized. These are classified as unknown and exit the pipeline without further processing.
This triage step ensures that only verifiable citations consume sourcing resources, while non-checkable citations receive appropriate labels without unnecessary processing.
Stage 3 - Sourcing
After triage, verifiable citations enter a source retrieval and matching pipeline:
- Candidate Retrieval. The system runs three different queries to maximize the number of potential matches.
- Local database search. The citation is first checked against GPTZero's internal database of indexed sources.
- Citation API query. The citation is checked against external bibliographic APIs using extracted metadata such as title, authors, and DOI.
- Internet-scale web retrieval. The citation is checked against the results of targeted web searches.
- Candidate ranking. Results from all three retrieval paths are pooled and ranked by similarity to the parsed citation. The top candidates advance.
- Metadata extraction. For each top candidate, bibliographic metadata is extracted from the source and aligned with the available components of the original citation.
Stage 4 - Context aware component matching
Per-component comparison is a critical stage in the pipeline, since the accuracy of these labels determines the veracity of the final classification (according to deterministic rules). At this step, the original citation is compared against each of the top candidate sources on a component-by-component basis. Six components are compared: title, authors, publisher/journal, publication date, URL, and DOI. Each component pair receives one of the following labels: match, partial match, not match, or unknown. The authors component also supports a weak match label for greater granularity. If either the citation or the source lacks a given component, the unknown label is assigned for that pair automatically.
This stage is context aware because surface-level string comparison breaks down quickly. For instance, the titles "Harry Potter and the Philosopher's Stone" and "Harry Potter and the Sorcerer's Stone" differ by one word but refer to the same book under different regional titles (they should match), while "The Girl with the Dragon Tattoo" and "The Girl with the Golden Tattoo" also differ by one word yet refer to entirely different works (they should not match). Since component pairs with the same edit distance may require opposite labels, each pair is judged using lexical similarity and semantic reasoning rather than edit distance alone.
Stage 5 - Taxonomy based classification
In the final stage of the pipeline, the per-component matching results from Stage 4 are mapped to a single output class using a formal taxonomy. The taxonomy defines five classes: exist, exist with minor issues, fake, unknown, and unsure. The formal definitions of each class are given in the next section.
The classification logic is governed by a tiered component hierarchy that assigns each citation component to one of four importance tiers:
- Tier 1 (Critical): Author, Title
- Tier 2 (Important Identifiers): URL/DOI (including arXiv identifiers)
- Tier 3 (Supporting): Publisher/Journal, Publication Date
The tier assignments reflect the relative diagnostic value of each component for determining citation veracity. Tier 1 components (author and title) are the strongest signals: a citation with authors and title that match a real source should be classified as exist, while mismatches in these fields are strong evidence of fabrication. Tier 2 components provide high-confidence verification when available, but aren't included in all citations. Tier 3 components contribute supporting evidence but are insufficient on their own to confirm whether a citation points to a real source.
Taxonomy
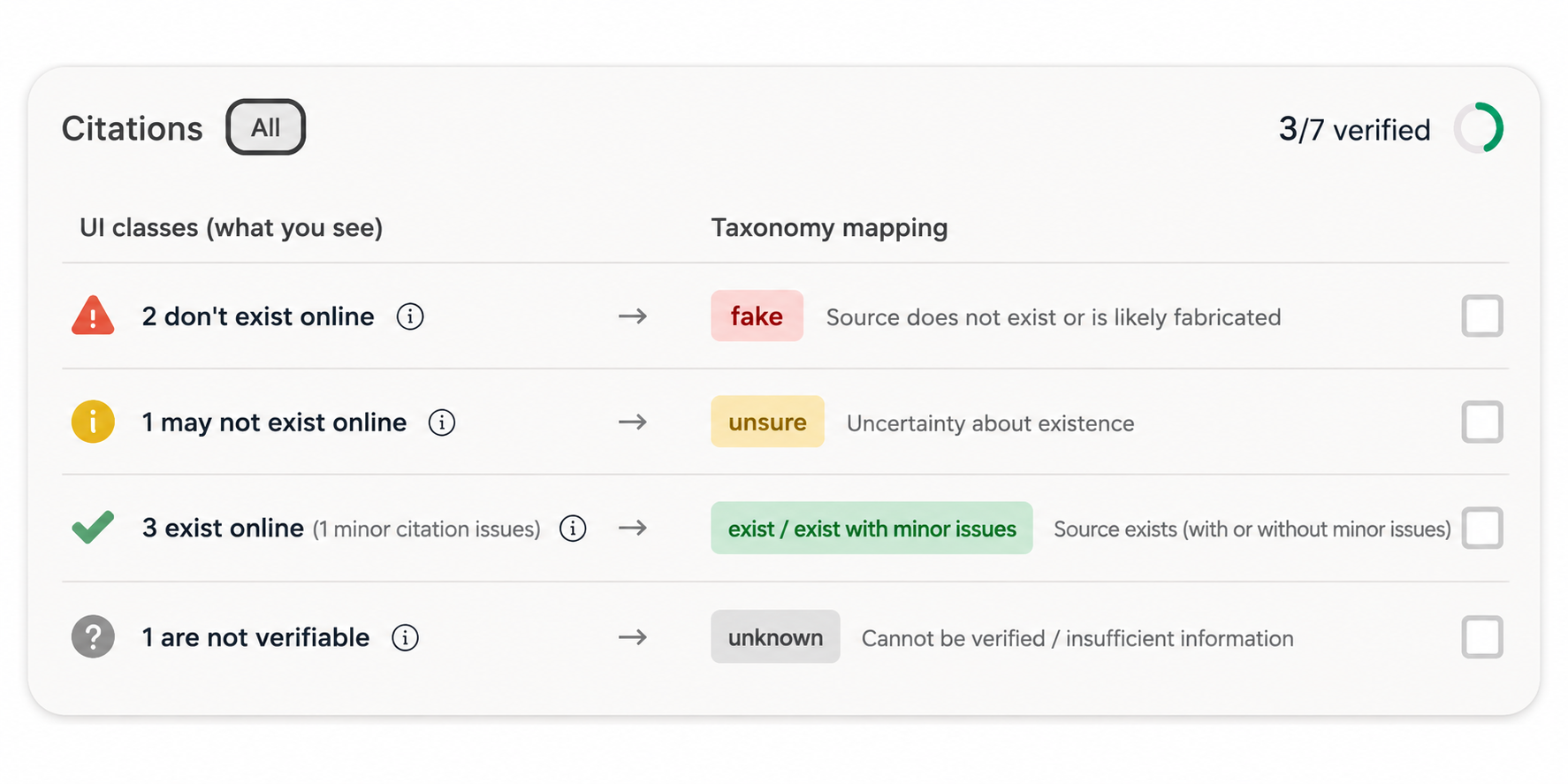
This section provides the formal definitions of the five output classes. Each definition is expressed as a flowchart requiring certain per-component match labels (match, partial match, not match, weak match, unknown) at specific tiers of the component hierarchy.
Exist
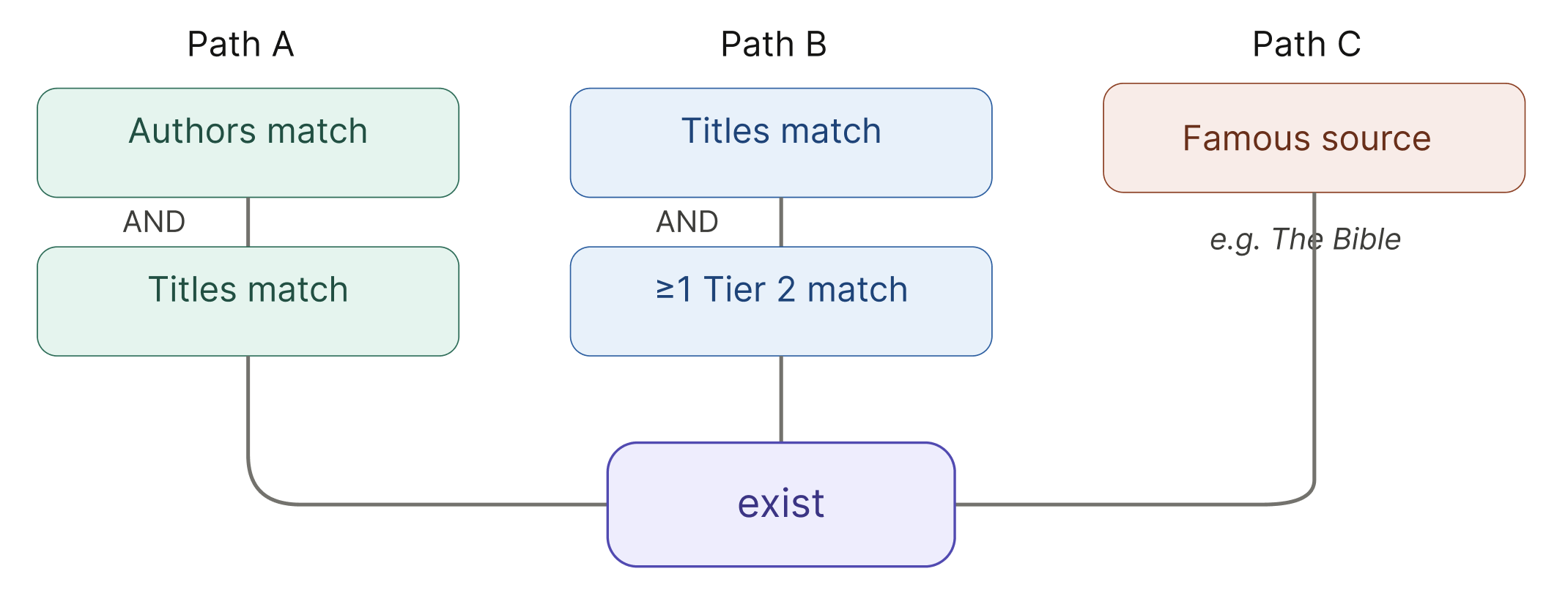
A citation is classified as exist if certain citation components “match” certain source components. Specifically, a citation exists if any of the following conditions are true:
(a) The authors and titles match.
(b) Titles match, AND one or both lack authors, AND at least one Tier 2 component (URL or DOI) match.
(c) The citation refers to a very famous source (for example, The Bible).
Note that for the purpose of this definition, match includes cases with minor differences (e.g., abbreviations or regional title variants).
Exist with Minor Issues
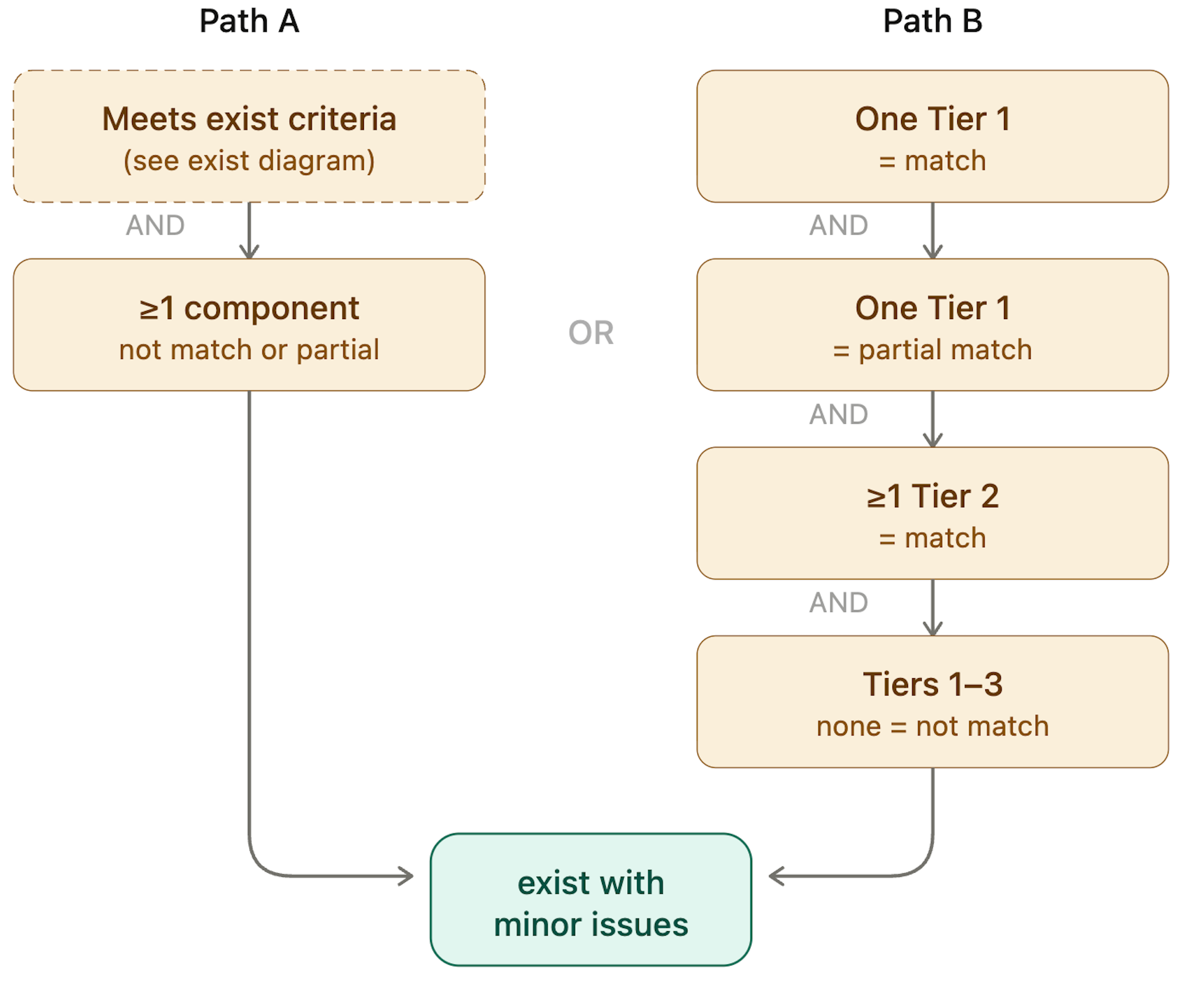
A citation is classified as exist with minor issues if:
(a) The citation meets the definition of exist, BUT at least one labeled component (Tiers 1–3) is not match or partial match.
OR
(b) All of the following are true:
- One Tier 1 component = match
- One Tier 1 component = partial match
- At least one Tier 2 component = match
- No labeled component = not match.
This class captures citations that refer to real sources but contain probably human errors — for example, a correct title and DOI but an incorrect publication year, or matching authors with a slightly truncated title. It tells users that the source exists, but the citation needs correction.
Fake
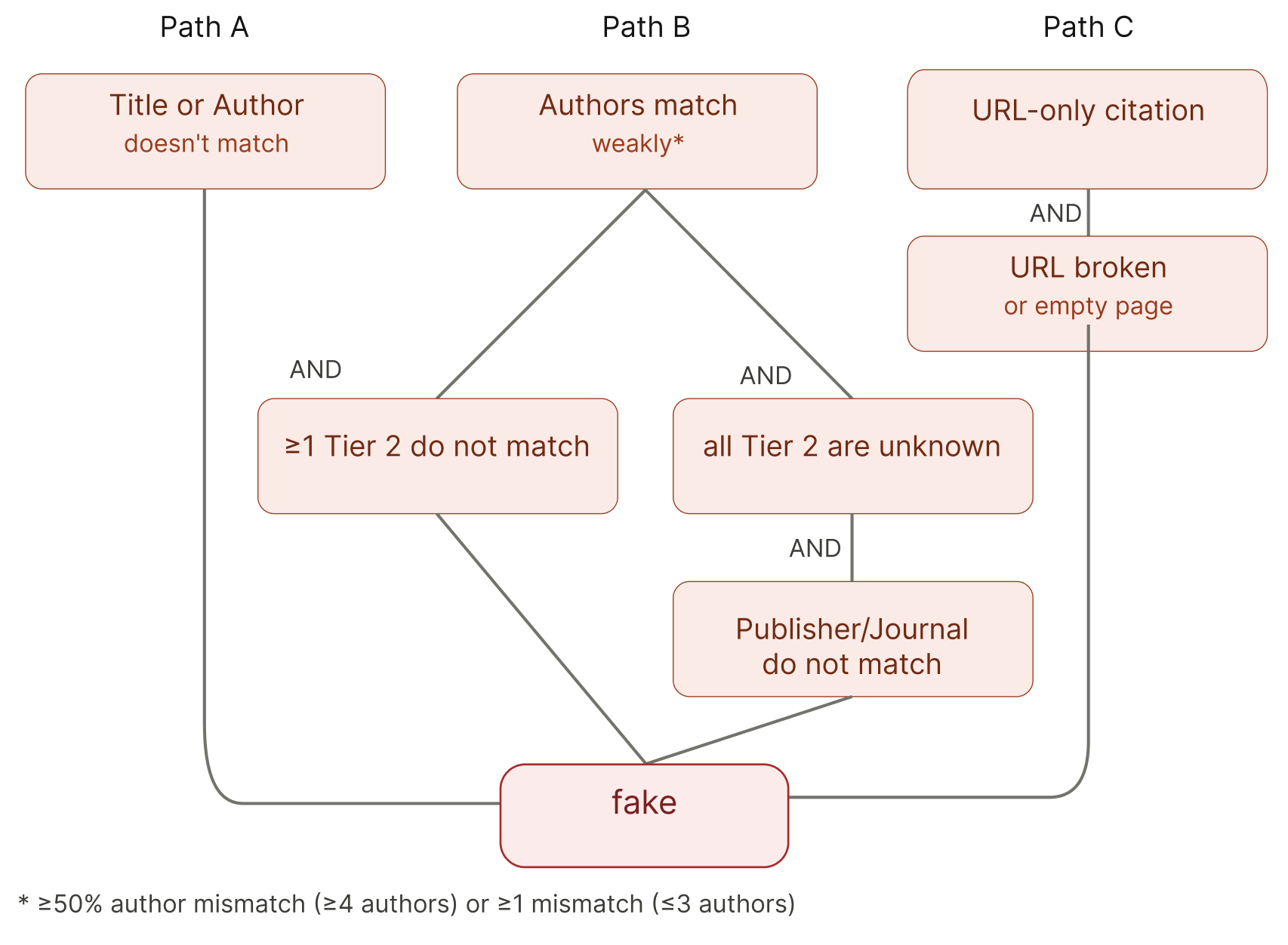
A citation is classified as fake if any of the following conditions are true:
(a) Either authors or titles do not match
(b) Authors match weakly, AND
- at least one Tier 2 component does not match, OR
- all Tier 2 components are labeled unknown AND Publisher/Journal does not match.
(c) The citation consists only of a URL, AND the URL is broken or leads to an empty page.
Unknown
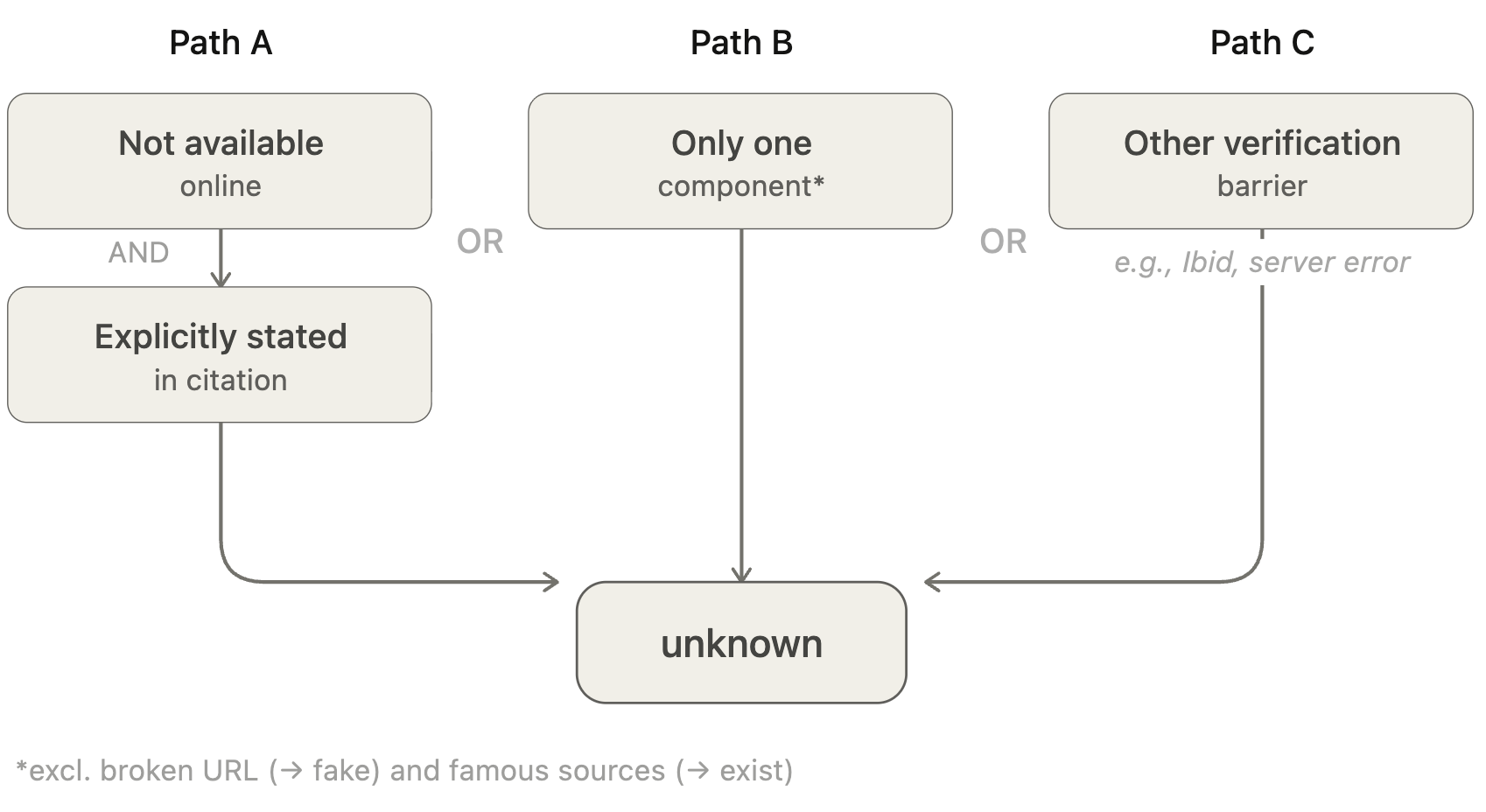
A citation is classified as unknown if:
(a) It is not possible to verify the citation because the source does not exist online and the citation explicitly indicates this (e.g., unpublished lecture notes, private correspondence, archival materials that are not publicly accessible).
OR
(b) The citation does not include enough information to make an assessment because it consists of only one component (except for very famous titles, which may be classified under exist, and citations consisting only of a broken URL, which are classified as fake).
OR
(c) Any other condition that prevents the system from completing verification (e.g., "Ibid," or cases where the source is temporarily unavailable).
Unsure
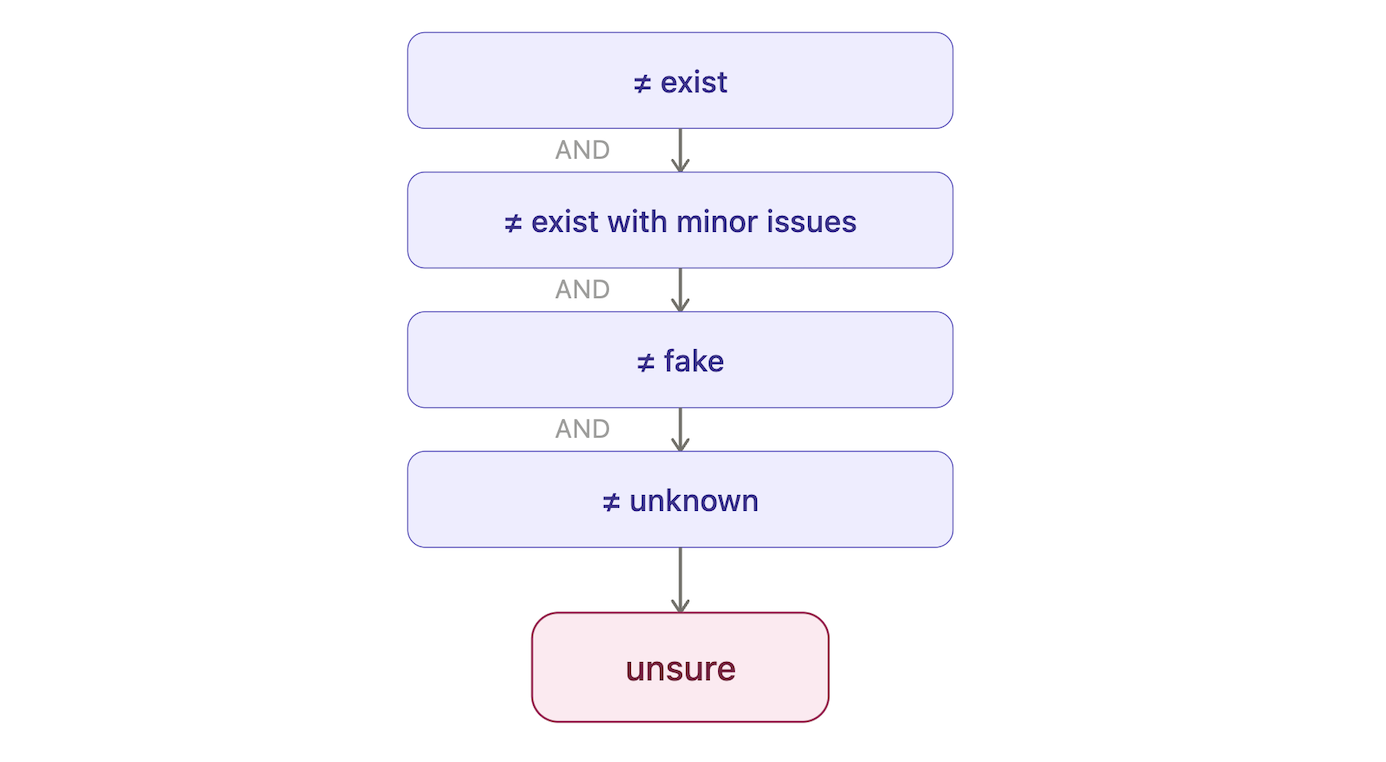
A citation is classified as unsure if it does not meet the criteria for any of the above four classes. This class serves as a catch-all for ambiguous cases.
Results
Dataset
The system was evaluated on two complementary datasets that each target a distinct failure mode: an adversarial set of 98 citations, and a clean set of 419 citations.
Adversarial set (n = 98). A curated set of real and hallucinated citations drawn from previous GPTZero investigations into government documents, consulting reports, and academic conference submissions. These citations were chosen for domain diversity and case complexity — namely, their ability to defeat naive verification. Example issues in this set include authors with modified surnames, paraphrased titles, fabricated DOIs, and/or plausible (but fake) journals or publishers. Each citation was independently reviewed by at least two of twelve annotators, with disagreements resolved by discussion.
The adversarial set label distribution:
- fake — 52 citations (53%)
- exist — 27 citations (28%)
- exist with minor issues — 11 citations (11%)
- unsure — 7 citations (7%)
- unknown — 1 citation (1%)
Over 85% of the citations in this set were classified as formally verifiable during triage. The remainder were routed to the reasoning and non-checkable paths.
Clean set (n = 419). A second dataset extracted from published, peer-reviewed academic papers that was compiled to measure the false positive rate at a larger scale. Every citation in this set refers to a real source, so any fake classification is a false positive. Evaluations on this set target one of the two fail states most consequential for users — incorrectly flagging a genuine citation as a fake.
Adversarial set results
Table 1. Per-class classification performance on the adversarial dataset.
| Class | Precision | Recall | F1 |
|---|---|---|---|
| exist | 79.3% | 85.2% | 82.1% |
| exist with minor issues | 62.5% | 45.5% | 52.6% |
| fake | 96.1% | 94.2% | 95.1% |
| unsure | 62.5% | 71.4% | 66.7% |
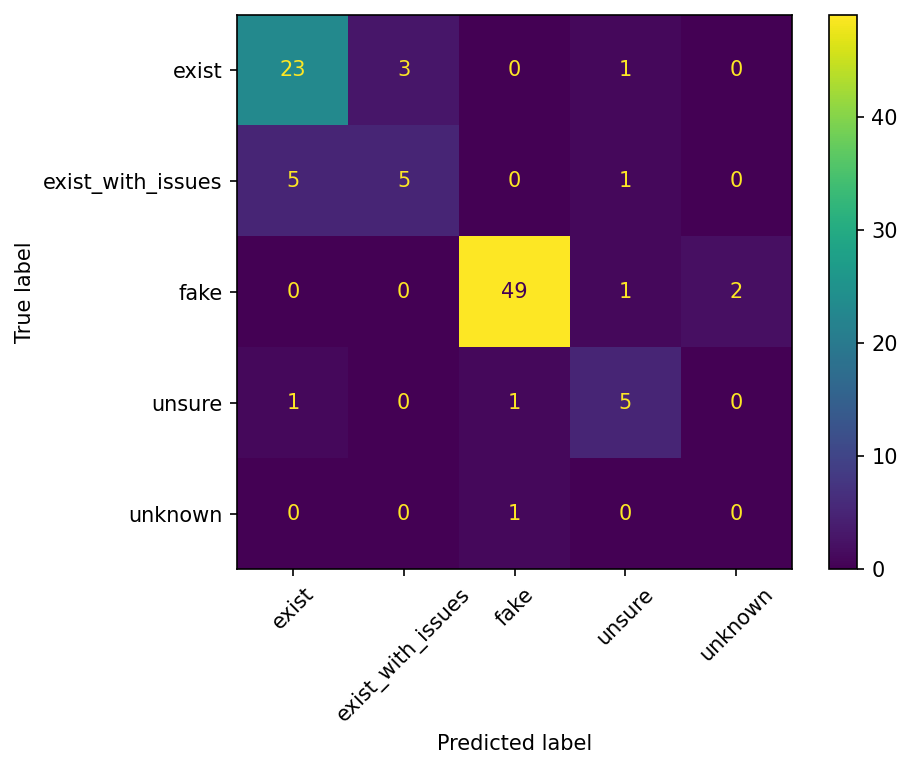
The confusion matrix reveals several notable patterns:
Hallucination Check detects fake citations with high accuracy. These results — 96.1% precision and 94.2% recall on citations verified as fake — represent the strongest performance across all classes. In short, if a text contains fake citations, the system will find them.
Hallucination Check also detects real citations accurately if exist and exist with minor issues are considered jointly. The division between these two classes exists to surface minor citation errors for users, and does not impact the core value of Hallucination Check as a system for citation verification.
False Positive Analysis on Trusted Citations
Table 2. Results on 419 trusted published citations.
| Predicted class | Count | Percentage |
|---|---|---|
| Match (exist / exist with minor issues) | 389 | 92.8% |
| Partial match | 26 | 6.2% |
| Not match (fake) | 2 | 0.5% |
| Unknown | 2 | 0.5% |
The false positive rate is 0.5% — only 2 out of 419 verified citations were incorrectly classified as fake. This is critical for practical deployment: a system that frequently flags real citations as fabricated would quickly erode user trust.
92.8% of citations were correctly identified as matching a real source. The 26 citations (6.2%) classified as partial match represent cases where the system found a likely source but identified metadata discrepancies between the citation as written and the source as retrieved — these may reflect genuine minor errors in the original published citations (e.g., slight title variations, missing co-authors) rather than system errors. The 2 citations classified as unknown (0.5%) represent cases where the system could not locate a matching source online, likely due to sourcing coverage limitations rather than fabrication.
Conclusion
GPTZero’s Hallucination Check is the result of collaboration between a diverse team of engineers, designers, domain experts and academic consultants. This diversity of perspectives motivates GPTZero's commitment to both high levels of verification accuracy and classification transparency. The key design choices — a five-class citation taxonomy, component importance hierarchy, context aware matching, and pre-verification triage router — reflect these commitments.
Hallucination Check turns vibe-citation detection — historically a matter of expert intuition — into a deterministic pipeline with formal rules and a sub-1% false positive rate. That accuracy threshold is what makes the system usable in environments where flagging a real citation has real costs: top-tier academic venues including ICLR, IJCAI, ICSE, COLM, and ICRA already rely on it as part of their review workflow, alongside use by students, educators and researchers.