GPTZero AI Detection Benchmarking: The Industry Standard in Accuracy, Transparency and Fairness

Overview
Welcome to GPTZero’s standardized benchmarking page. Here you’ll find the results of a comprehensive evaluation of our AI detector across a variety of domains, LLMs, and languages. Evaluations are updated quarterly, and raw predictions are available for researchers interested in reproducing results.
One of the goals of this post is raise the standard for transparency across the entire AI detection industry. We believe that greater transparency will both increase the rigor and credibility of the industry and reveal what we already know: that GPTZero’s detector is the most accurate solution available. Table 1 summarizes performance metrics across 5 domains showing that GPTZero has the best performance of any commercially available AI detector on the latest generation of LLMs.
Table 1: Average performance metrics across 4 domains
Benchmarking Philosophy and Transparency
At GPTZero, we strive to be as rigorous and fair as possible in our evaluations so that users can easily decide if our detector meets their needs. This informs how we construct benchmarks, evaluate competitors, and provide API access to our detector for evaluation purposes.
Benchmark Construction
The following procedure is used to construct each benchmark dataset:
- Select N human texts from our large database of human texts. We take steps to ensure that these texts were not included when training our model to avoid data leakage
- Generate AI versions of each human text using a variety of prompts designed to match the details of the human text while varying tone and structure
Each selected text meets the minimum length requirement of 250 characters (approx. 50 words) specified on the GPTZero dashboard. Although other detectors have higher minimum length requirements, they allow texts shorter than that limit to be scanned via their API. We believe that our smaller minimum character limit is advantageous for users scanning reviews or social media posts, and pushes the cutting edge of what can be detected.
We make (almost) every benchmark publicly available, offering an unprecedented level of transparency for commercial detectors. One caveat is that benchmarks containing data that was challenging to obtain are restricted to researchers. Please contact us here for access to these restricted benchmarks.
Detector Versioning
GPTZero is the most regularly updated AI detector available, as shown by the 15 different model releases in 2025. Releases are motivated by expansion to new text domains, improved robustness to new humanization techniques, and new capabilities such as distinguishing between fully LLM generated text and human text that was polished by an LLM.
Besides updates, our detector generalizes well such that new LLMs are often easily detected without requiring an update.
With this in mind, AI detection benchmarking requires being precise about the underlying model version. Blog posts from competitors, and even academic papers treat AI detectors like static models which are never updated. This often results in meaningless comparisons.
For example, the paper People who frequently use ChatGPT for writing tasks
are accurate and robust detectors of AI-generated text uses the version 2025-01-09-base of GPTZero, but does not mention this anywhere. To find this information, one has to dig into the Github repository which has the raw API outputs.
Notably, the model version of the other detectors evaluated (such as Pangram) are not even listed. Results presented this way can be misleading, and read as if they are reflective of current, rather than historical, model performance.
This approach to versionless benchmarking is markedly different from the evaluation of LLMs which are meticulously versioned. For example see this comparison of Gemini 3 pro against other models. It would not make sense to claim to have benchmarked GPT vs Gemini since there are many different versions of these models.
Our dedication to technical rigor and transparency inspires how we tag both our own model and competitors in our evaluations. For every AI detector evaluated, we add a suffix in parenthesis indicating the respective model version (if the API response contains it) or the date it was evaluated on if the model version is not explicitly returned.
GPTZero is leading the way with honest, transparent versioning of our detector as well as competitors. Importantly, we update our evaluations of competitors quarterly with their most recent version, ensuring that benchmarking results are up to date. We do so because we’re motivated by the integrity and rigorous academic background of our team, as well as the confidence we have in being the best AI detector available and our fast model adaptation abilities.
Evaluation Accessibility
We commend competitors such as Originality and Pangram for providing API access to their detectors for evaluation purposes. TurnItIn, on the other hand, makes it impossible to evaluate their detector by limiting access only to educators. Similarly, Copyleaks has blocked our account, claiming that our evaluations are against their terms of service.
When evaluation access is gated, users and researchers have no way to verify claims or compare methodologies, increasing the risk that the results are biased. It is understandable that AI detection services want to prevent the use of “humanizers” exploiting the outputs of their models. However, we strongly believe that good faith benchmarking between competitors gives users the ability to make an informed decision about which solution is best for them.
API Reliability
We have noticed that some detectors have APIs which are extremely slow, sometimes taking over 30 seconds to scan even a short text. We do our best to fairly evaluate such APIs, using generous timeouts. In the case where these services are unable to serve a request, we exclude the text from the metrics computed for that detector. We indicate the percentage of requests that were successfully completed along with every evaluation result.
Metrics and Binarization
GPTZero was the first commercial AI detector to frame AI detection as a multiclass classification problem, offering a third “Mixed” class as a prediction since mid-2023. This unprecedented level of granularity means that GPTZero can accurately find the boundary between human and AI text such as when assignment questions are followed by AI responses.
GPTZero also distinguishes between AI-generated text, and human text that was polished by AI, as well as AI text that has undergone paraphrasing or humanization. As a result, the GPTZero classification taxonomy looks like this:
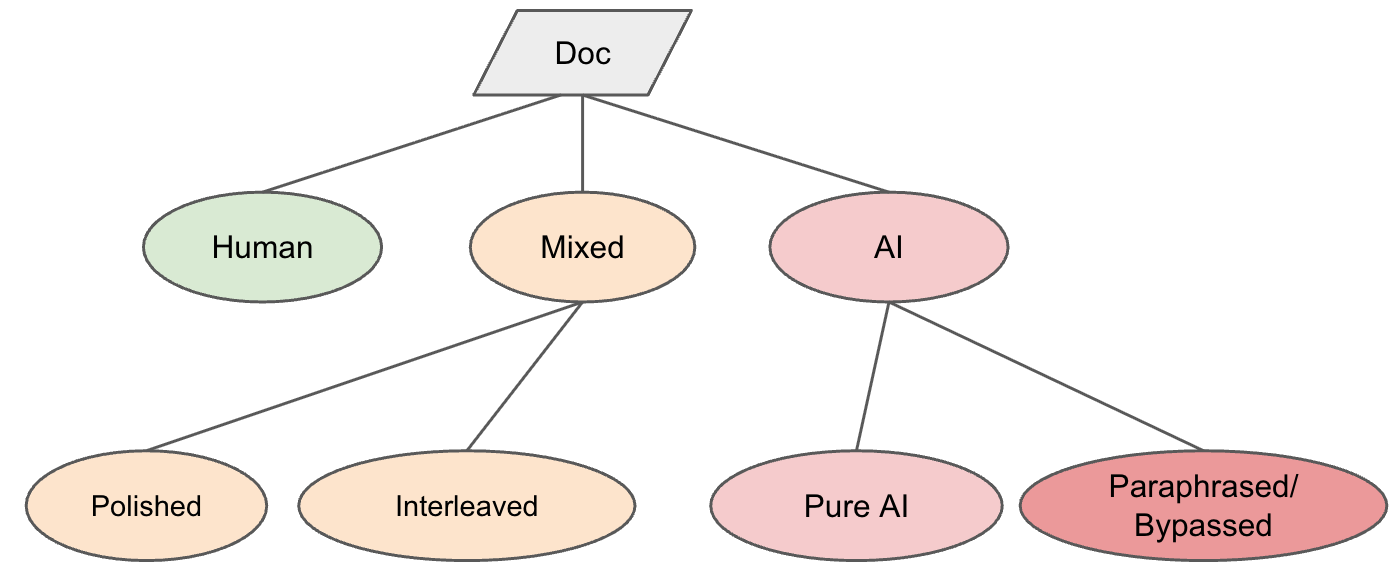
This creates a challenge when benchmarking against other detectors which do not use a multiclass taxonomy. We standardize predictions using the following mapping to binarize our detector’s outputs
GPTZero Mapping
- Human → Human
- Mixed (Concatenated) → AI
- Mixed (Polished) → AI
- AI (Pure AI) → AI
- AI (Paraphrased) → AI
where any class that indicates some amount of AI content is considered to be AI.
Pangram Mapping
Pangram recently introduced a multiclass output, as indicated by their “prediction_short” field which can be either one of “AI”, “Human”, or “Mixed”. We use the following mapping for Pangram to binarize their outputs
- Human → Human
- Mixed → AI
- AI → AI
Originality Mapping
Originality frames AI detection as a binary problem, though their API response is based on chunks which can vary in AI classification. For an overall document, we use the “ai.classification.ai” field where if it is set to
- 1 → AI
- 0 → Human
Metric Descriptions
The confusion matrix below illustrates predictions on a dataset comprising 2000 total texts:
- 1000 are human - 995 are predicted as human and 5 are predicted as AI
- 1000 are AI - 990 are predicted as AI and 10 are predicted as human
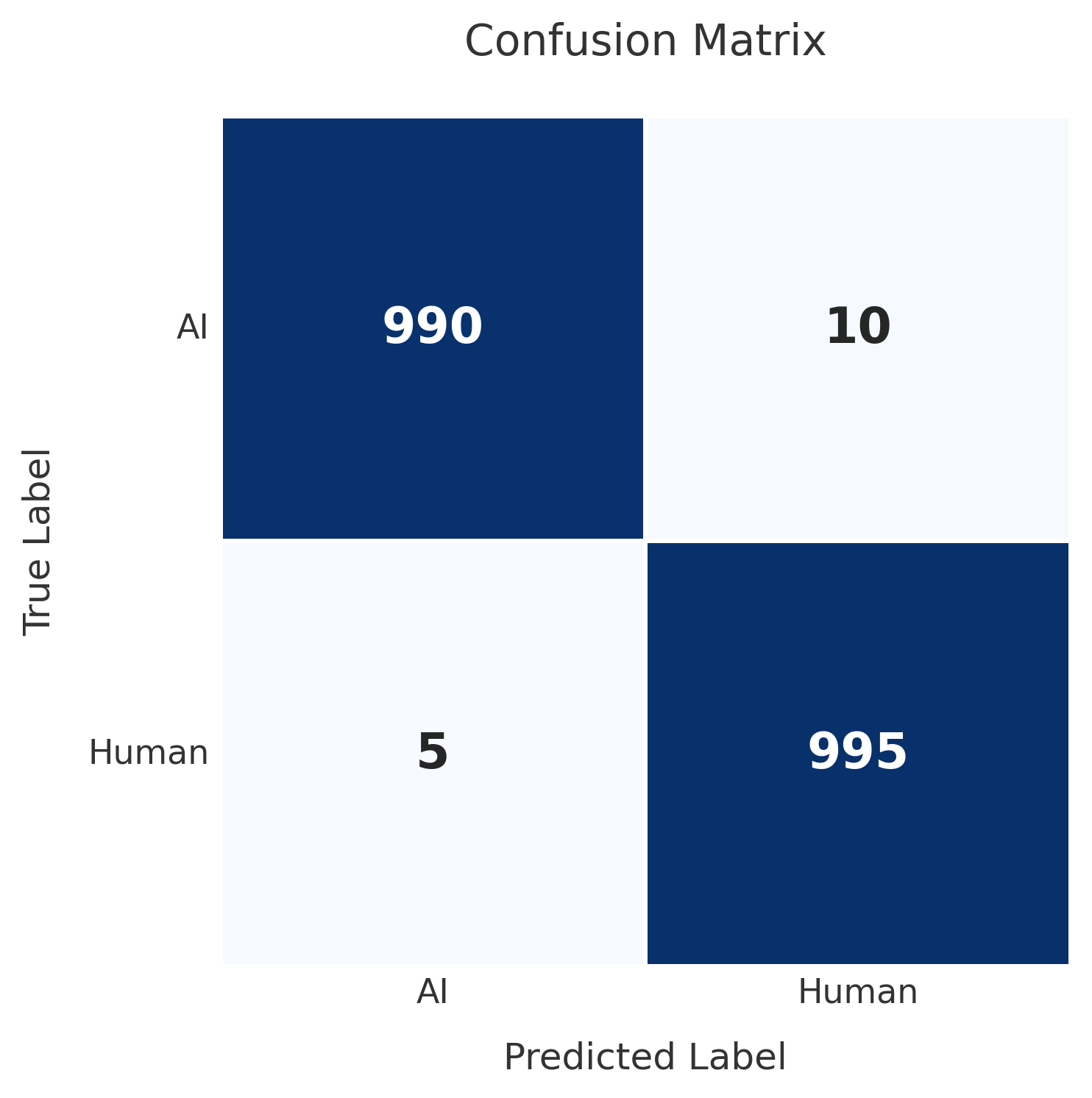
We define a “positive” example as one that is labeled as AI, and a “negative” example as one that is labeled as human. This results in the following 4 types of predictions
True Positive (TP): An AI text correctly predicted as AI.
False Positive (FP): A human text incorrectly predicted as AI.
True Negative (TN): A human text correctly predicted as human.
False Negative (FN): An AI text incorrectly predicted as human
These prediction types are then used to define the following metrics.
Recall: The percentage of AI texts correctly predicted as AI.
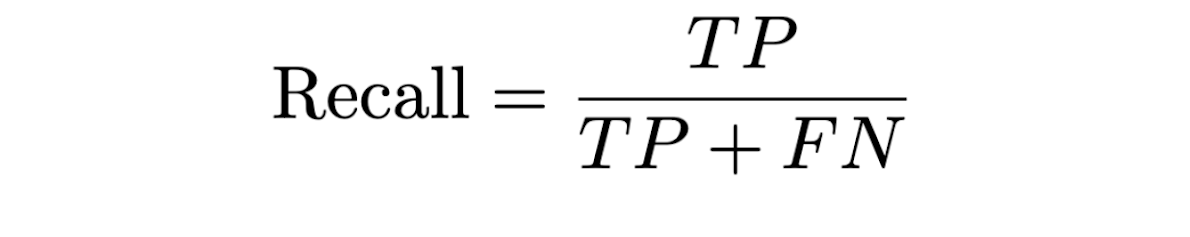
False Positive Rate (FPR): The percentage of human texts misclassified as AI.
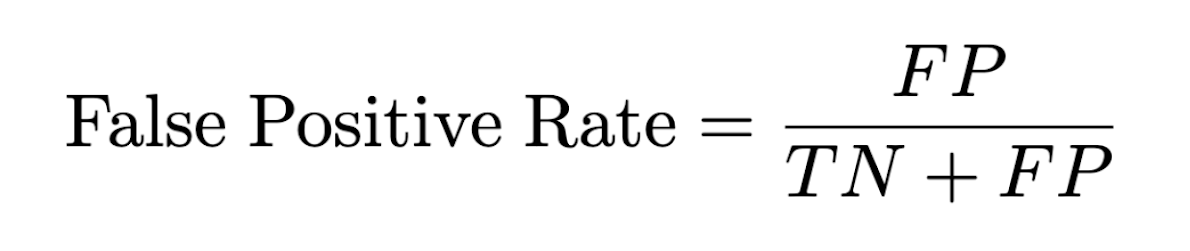
Precision: Of the texts predicted to be AI, how many of them are actually AI.
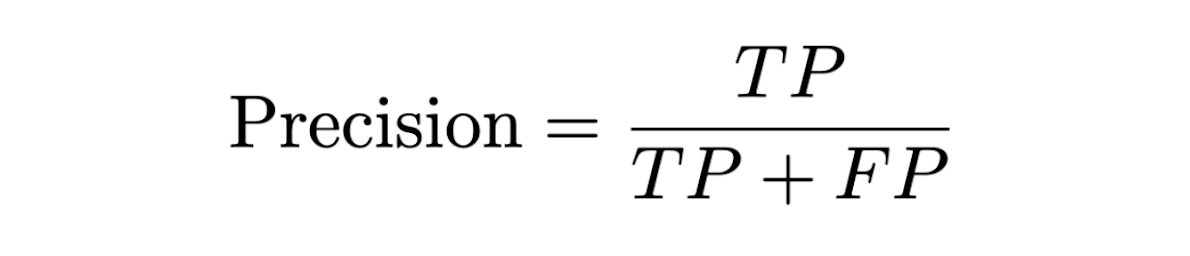
Accuracy: The percentage of texts correctly classified
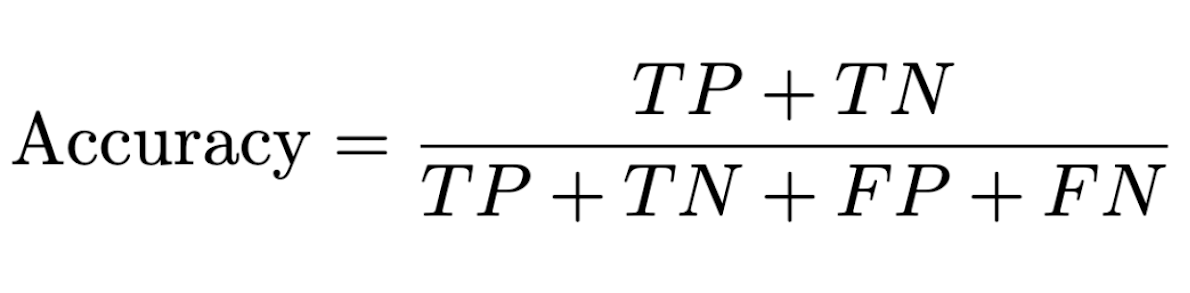
Per Domain Performance
GPTZero’s detector is trained on text from many domains including academic papers, essays, news articles, creative writing, blog posts, social media posts, and legal documents, among others. These domains cover the majority of document types that our users scan. We show detection results on a variety of domains below.
All benchmarks in this section use the latest generation of language models from the most popular providers
- GPT-5.2
- Gemini 3 Pro
- Claude Sonnet 4.5
- Grok 4 Fast
(This set of LLMs is updated quarterly. Each benchmark consists of 1000 human texts and 1000 LLM-generated texts, generated uniformly across providers [250 texts per LLM].)
Academic Paper Reviews
We scraped OpenReview for ICLR reviews, rebuttals, and responses to rebuttals prior to 2022 (filtering out possible AI data contamination). The data is entirely focused on machine learning papers, but offers a variety of formatting in terms of equations, tables, markdown, etc. which might trigger less robust detectors to predict AI.
GPTZero has a superior FPR and recall on this data as shown in Table 2, It is worth noting that Originality’s 5% FPR would be unacceptable for this text domain, and we recognize that Originality focuses on marketing/SEO content. Pangram’s lower recall is unsurprising given the low recall on academic papers as well.
Predictions can be found here.
Table 2: Academic Paper Reviews Performance Metrics
Creative Writing
Our creative writing dataset consists of web-scale data filtered specifically for creative writing contexts. Due to data usage policies and copyright constraints, the raw textual data cannot be made available for commercial republication.
While we cannot publicly host the full dataset, we are happy to provide qualified researchers with access to the underlying data for non-commercial verification and reproducibility purposes.
GPTZero performs slightly better than Pangram in terms of recall, and does much better than Originality as seen in Table 3.
Table 3: Creative Writing Performance Metrics
Essays
Our essay dataset consists of web-scale data filtered specifically for essays. Due to data usage policies and copyright constraints, the raw textual data cannot be made available for commercial republication. We select 1000 texts randomly from this filtered dataset for evaluation.
While we cannot publicly host the full dataset, we are happy to provide qualified researchers with access to the underlying data for non-commercial verification and reproducibility purposes.
Performance between GPTZero and Pangram is identical, while Originality has marginally lower recall as seen in Table 4.
Table 4: Essays Performance Metrics
Product Reviews
Our product review dataset consists of web-scale data curated specifically for product reviews. Due to data usage policies and copyright constraints, the raw textual data cannot be made available for commercial republication. We select 1000 texts randomly from this filtered dataset.
While we cannot publicly host the full dataset, we are happy to provide qualified researchers with access to the underlying data for non-commercial verification and reproducibility purposes.
GPTZero outperforms Originality and Pangram by a large margin, specifically in terms of recall, highlighting superior performance on shorter texts, as well as texts using informal language as shown in Table 5.
Table 5: Product Reviews Performance Metrics
Multilingual Performance
While the majority of GPTZero users scan English texts (>85% of texts), multilingual AI detection is a priority for GPTZero since the challenges that AI poses for proof of work are relevant regardless of language.
Our multilingual benchmark spans 24 languages and was constructed by combining data from the Multitude V3 AI detection dataset and the CulturaX dataset.
GPTZero surpasses Originality by a noticeable margin as shown in Table 6, and both Pangram and GPTZero have a much lower false positive rate than Originality, which would be unusable for most non-English cases.
Table 6: Multilingual Benchmark Performance
Bypasser Performance
The frontier of AI detection is being able to identify texts which have been modified by a bypassing service. Our internal testing indicates that many advanced users are attempting to preemptively bypass AI detectors. To provide accurate detection in this setting, GPTZero has conducted adversarial attacks on our own detector, identified patterns which could be leveraged by adversaries to manipulate predictions, and trained on modified AI texts to become robust to attacks.
We use a dataset of 1000 AI texts that have been modified by a variety of paraphrasing techniques and more than 12 dedicated bypassers services to quantify accuracy in this setting. This dataset covers several domains including academic writing, scientific text, essays, social media, and creative writing. The original AI text was generated by GPT-5, GPT4o, and GPT4.1.
Table 7 shows that GPTZero has significantly higher recall than both Originality and Pangram on bypasser texts. Originality does comparatively well compared to Pangra. This is in line with higher recall observed on non-bypassed texts, though that comes at the cost of too many false positives for typical use cases such as in education.
Table 7: Bypasser Benchmark Performance
