DeepSeek versus AI Detectors
GPTZero expands its AI detection coverage of LLMs to DeepSeek’s open-source reasoning model that made waves in the AI industry.

What is DeepSeek and why was everyone talking about it?
DeepSeek is a Chinese AI startup who released an open-source large language model in late January 2025 that launched AI advancement conversations back into mainstream consciousness, mostly because it caused a temporary stock market tumble in technology stocks like Nvidia, whose hardware powers a lot of AI chip computing.
Large US-based AI language companies like OpenAI and Anthropic release new updates to their popular chat models ChatGPT and Claude every few months. While ChatGPT o1, OpenAI’s latest model released in December 2024, performs comparable reasoning to DeepSeek’s model, DeepSeek claims to be much cheaper to train and run. It also performs as well, if not better, at advanced reasoning tests.
Whenever a new model of the AI is released, we get asked: what does this mean for AI detectors? Will this latest, advanced mode somehow be able to bypass GPTZero’s AI detection?
Can DeepSeek evade AI detection?
The short answer is no; our research and benchmarking shows that most AI detectors, particularly GPTZero, are very capable of detecting new AI models right out of the gate, even without any additional training or tuning.
DeepSeek is no different. While we have only been able to benchmark DeepSeek v3 so far, we performed similar benchmarks on ChatGPT o1’s advanced reasoning model and found similar results to our tests on DeepSeek.
This is because most LLMs aren’t being developed purely to bypass detection. Their goal is to be precise and accurate in their reasoning, but unless prompted otherwise by the user, their answers and responses tend toward specific patterns and styles that our AI detector is already tuned to expect.
How we benchmarked for DeepSeek
We tested one thousand human documents and one thousand AI documents from a DeepSeek v3 benchmark dataset and ran them through detectors. This dataset includes text written in various styles, including:
- Books
- Encyclopedia articles
- Blog posts
- Essays
- Social media pos
We calculated the instances where each tool accurately classified the text as human or AI, and noted when it misclassified human as AI text to make the false positive rate.
Results of Feb 2025 Benchmark: DeepSeek vs. AI Detectors
Results from our “Confusion Matrix”
A confusion matrix visualizes the accuracy of a detector’s predictions across an entire dataset. For example, the top left cell counts the number of human texts that were correctly predicted as human, and the bottom left cell counts the number of AI texts.
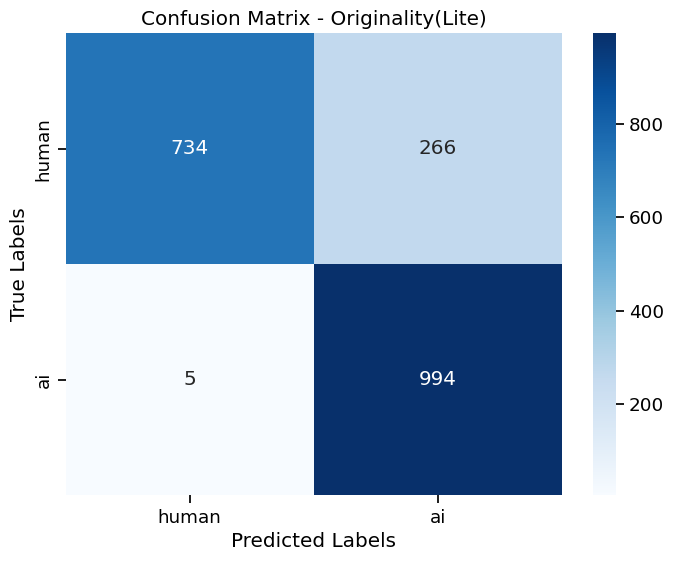
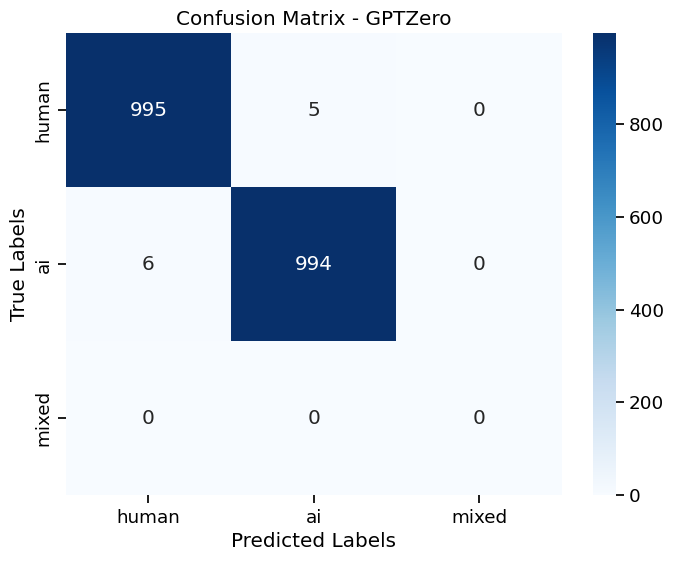
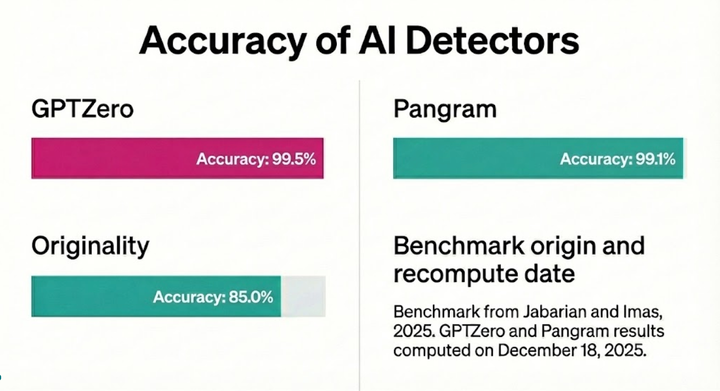
GPTZero had the highest accuracy and lowest instance of confusing AI and human text (0.05%).
*Recall
Recall is simply the percentage of AI generated texts that a detector is able to classify as AI. Typically higher recall is accompanied by a higher false positive rate. GPTZero maintains high recall with a low false positive rate.
GPTZero’s outlook on DeepSeek and the future of LLM reasoning
DeepSeek’s explosion into the AI landscape may have shaken the companies that build core models. That said, GPTZero strives to be agnostic and detect as many foundational and domain-specific models as our millions of users need–– from ChatGPT to paraphrasers and AI writing assistants. We believe that many companies like ours stand to benefit from cheaper, more affordable compute costs that DeepSeek offers.
We regularly update our detector to account for changes in LLM architecture, prompting techniques, and even underlying training paradigms; so we are always prepared to detect new models as they release. In the case of DeepSeek, no such update was needed, highlighting the ability of our detector to generalize to the new generation of foundation models. Our modelling approach and adaptation philosophy helps maintain our reputation as the most reliable transparency layer for information integrity, continuing as the “Turing test” for humanity in this increasingly AI world.